The Azure PostgreSQL Workshop
Welcome to the Azure PostgreSQL Workshop. In this lab, you’ll go through tasks that will help you master the basic and more advanced topics required to deploy and operate a PostgreSQL environment on Azure Database for PostgreSQL).
You can use this guide as a PostgreSQL tutorial and as study material to help you get started to learn PostgreSQL.
Theme: Deployment
- Azure Database for PostgreSQL Provisioning
- Data import and environment preparation
- Access and basic Administration in Azure Database for PostgreSQL
- Managing databases
- Roles and Permissions
Theme: Accessibility and Business Continuity
- Logical backup
- Back-ups/restore
- HA/DR
- Patching and maintenance windows
- Security Management in Azure Database for PostgreSQL
Theme: Day two operations
- Monitoring and Troubleshooting in Azure Database for PostgreSQL
- Deep dive into performance issue resolution and identify optimization fixes
- Multiversion Concurrency Control, MVCC
- Daemons & Tuning
- SQL characteristic
- Statistics and Queries
Prerequisites
Tools
You can use the Azure Cloud Shell accessible at https://shell.azure.com once you login with an Azure subscription. The Azure Cloud Shell has the Azure CLI pre-installed and configured to connect to your Azure subscription as well as psql and other Postgres utilities like pg_dump, createdb or createuser that will be used throughout the training, your access to the database might be through a jump-box in between cloudshell and PostgreSQL environment.
Azure subscription
If the workshop will run on your Azure subscription
Please use your username and password to login to https://portal.azure.com.
Also please authenticate your Azure CLI by running the command below on your machine and following the instructions.
az account show
az login
If the workshop will run on Azure Pass
- Login with a github account with the provided link: https://azcheck.in/xxxxxxx (Please use the provided one)
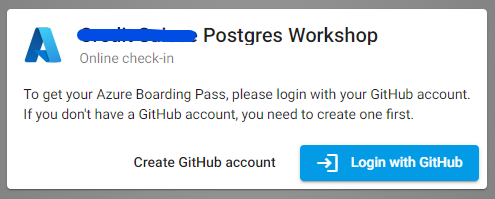
-
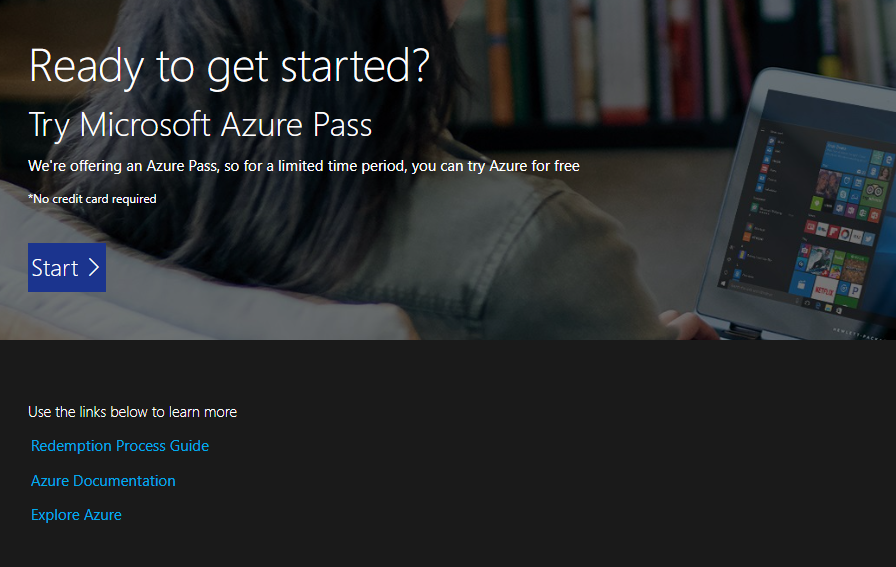
Follow the instructions, basically copy the code and go to: https://www.microsoftazurepass.com/ to redeem the voucher and click on Start>.
For more information follow : https://www.microsoftazurepass.com/Home/HowTo?Length=5
Azure Cloud Shell
You can use the Azure Cloud Shell accessible at https://shell.azure.com once you login with an Azure subscription.
Head over to https://shell.azure.com and sign in with your Azure Subscription details.
Select Bash as your shell.

Select Show advanced settings
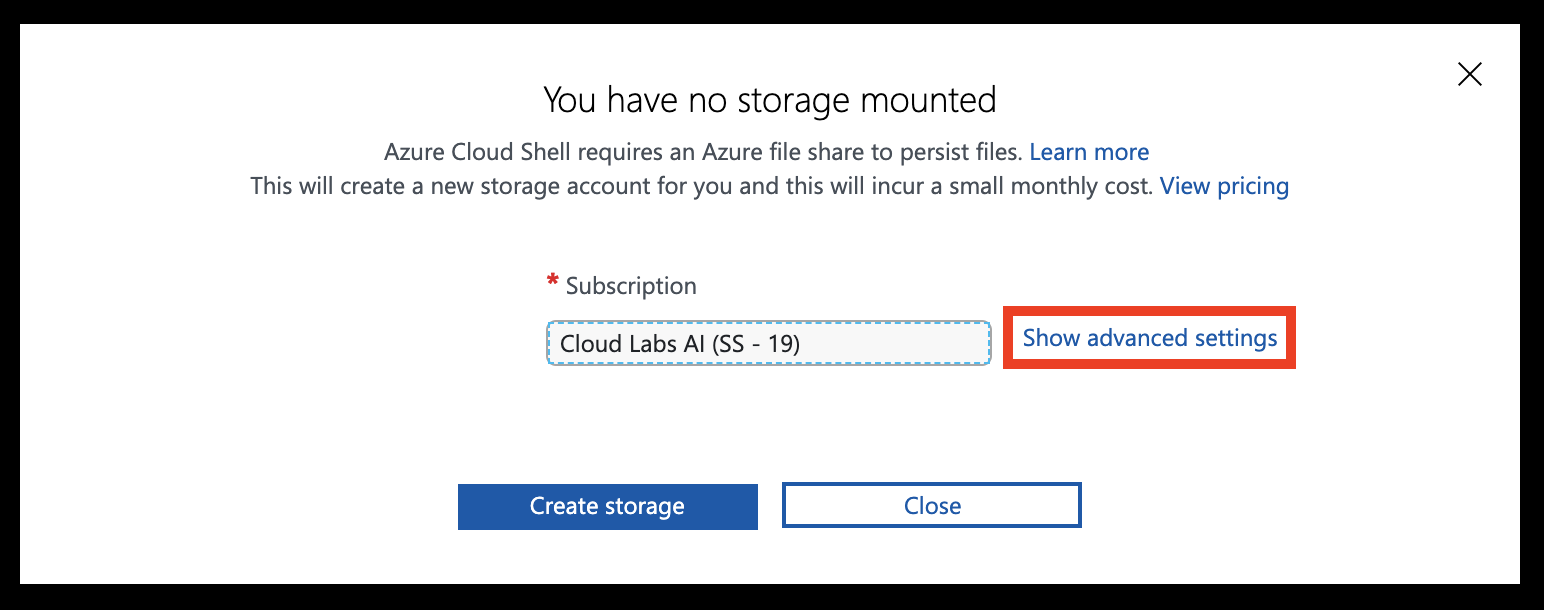
Set the Storage account and File share names to your resource group name (all lowercase, without any special characters), then hit Create storage
You should now have access to the Azure Cloud Shell
Tips for uploading and editing files in Azure Cloud Shell
- You can use
code <file you want to edit>in Azure Cloud Shell to open the built-in text editor. - You can upload files to the Azure Cloud Shell by dragging and dropping them
- You can also do a
curl -o filename.ext https://file-url/filename.extto download a file from the internet.
Workshop Overview
You will be deploying the below architecture using Bicep
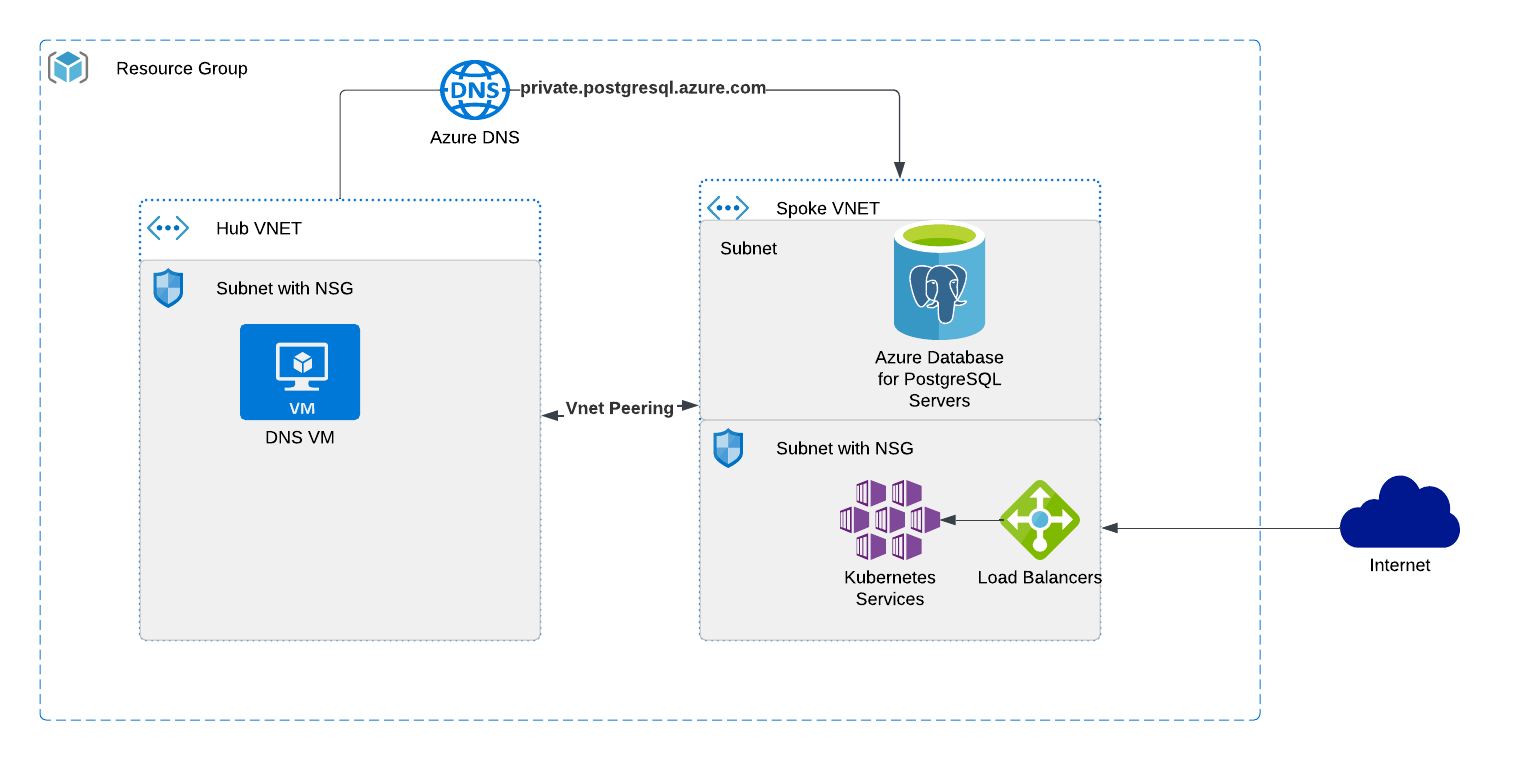
Based on the workshop that is running you might be deploying the Apache Superset application which is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill sets to explore and visualize their data, from simple line charts to highly detailed geo-spatial charts.that is containerized and is architected for a microservice implementation.
Getting up and running
Deploy Azure Database for PostgreSQL with Azure Portal
Azure Database for PostgreSQL is a fully-managed database as a service with built-in capabilities, such as high availability and intelligence.
Tasks
- Use Bicep to deploy Azure Database for PostgreSQL - Flexible server.
- Use Azure Cloud Shell to connect to DNS VM then you can access the Azure PostgreSQL database..
Setup Database
Deploy DB using Bicep
Deploy Azure Database for PostgreSQL, which is managed service that you can use to run, manage, and scale in the cloud.
Based on the previous section, the cloudshell environment should be available, log to your cloudshell - bash. the next step is to install bicep
az bicep install
Download the bicep templates for the workshop
wget https://pg.azure-workshops.cloud/scripts/bicep.zip

Uncompress the the downloaded file
unzip bicep
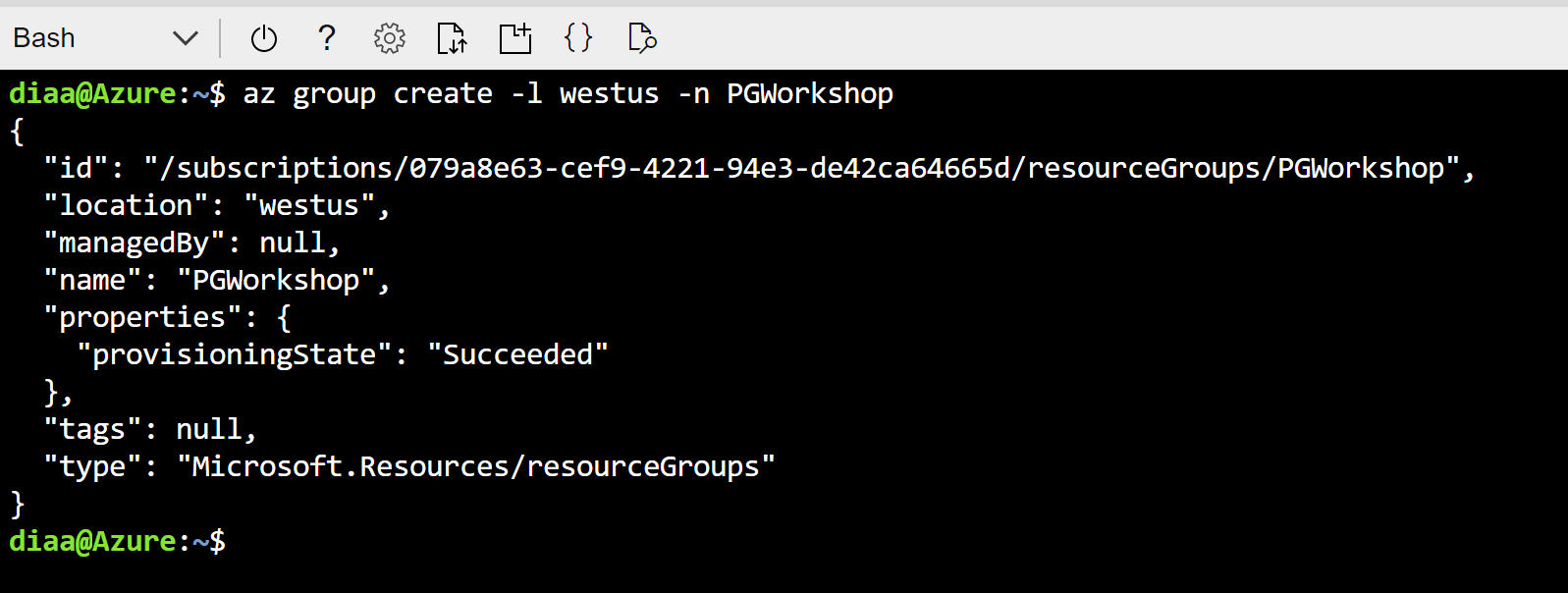
Create a new azure resource group to deploy the workshop resource in this resource group. Please take note of the resource group name in this below command it will be PG-Workshop.
az group create -l Eastus -n PG-Workshop
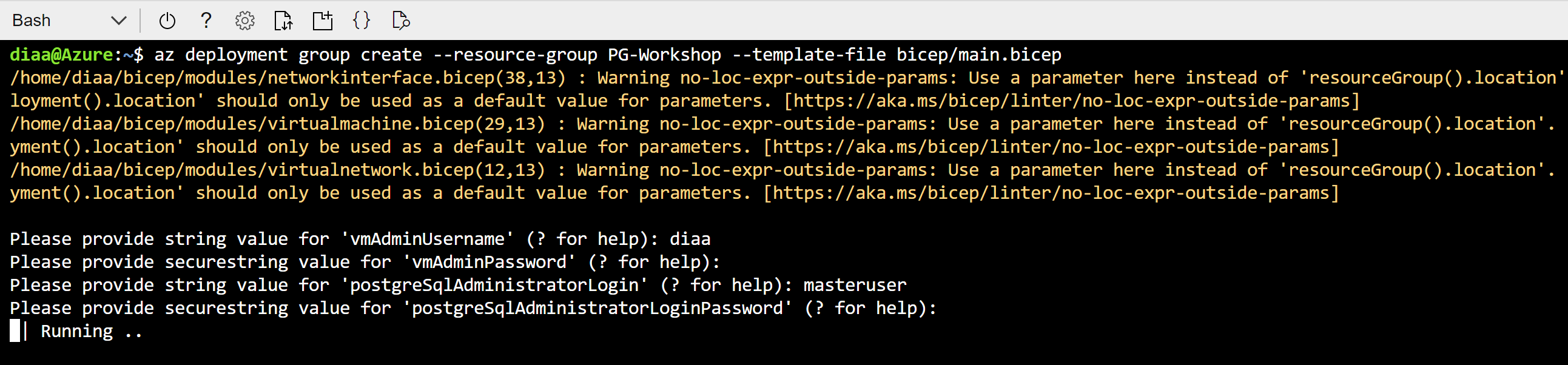
In this step we will deploy the bicep template to the resource group that we created in the previous step
az deployment group create --resource-group PG-Workshop --template-file bicep/main.bicep
You will be asked for 4 questions
- Admin username for the Jump-box (DNS)
- Admin password for the Jump-box
- Admin username for the PostgreSQL database (use your name rather than admin/root)
- Admin password for the PostgreSQL database (Please use strong password)
It will take a while to deploy the environment, when it finish you should see long output mentioning succeeded in the last 10 lines.
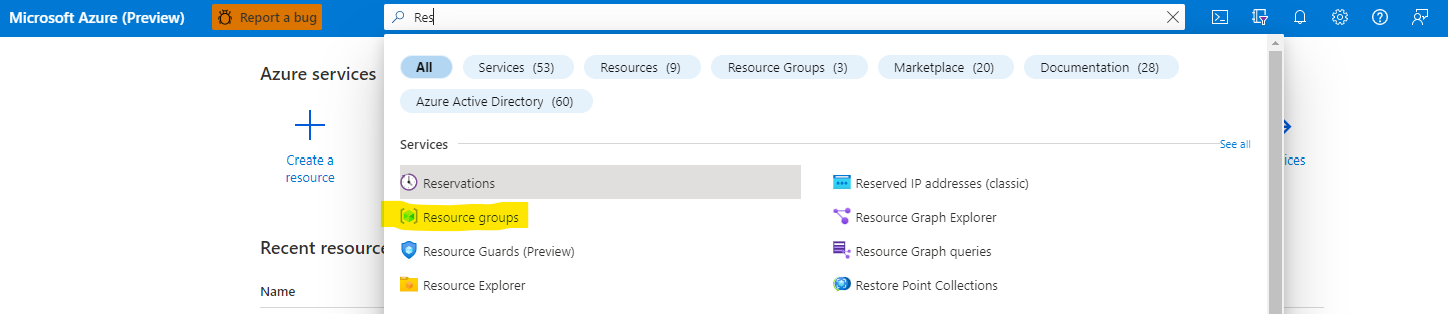
After the creation process finished you should be able to see the resource in the resource groups, go to Resource Groups
Click on the resource group name that we created, PG-Workshop if you didn’t change the az command to create the resource group.
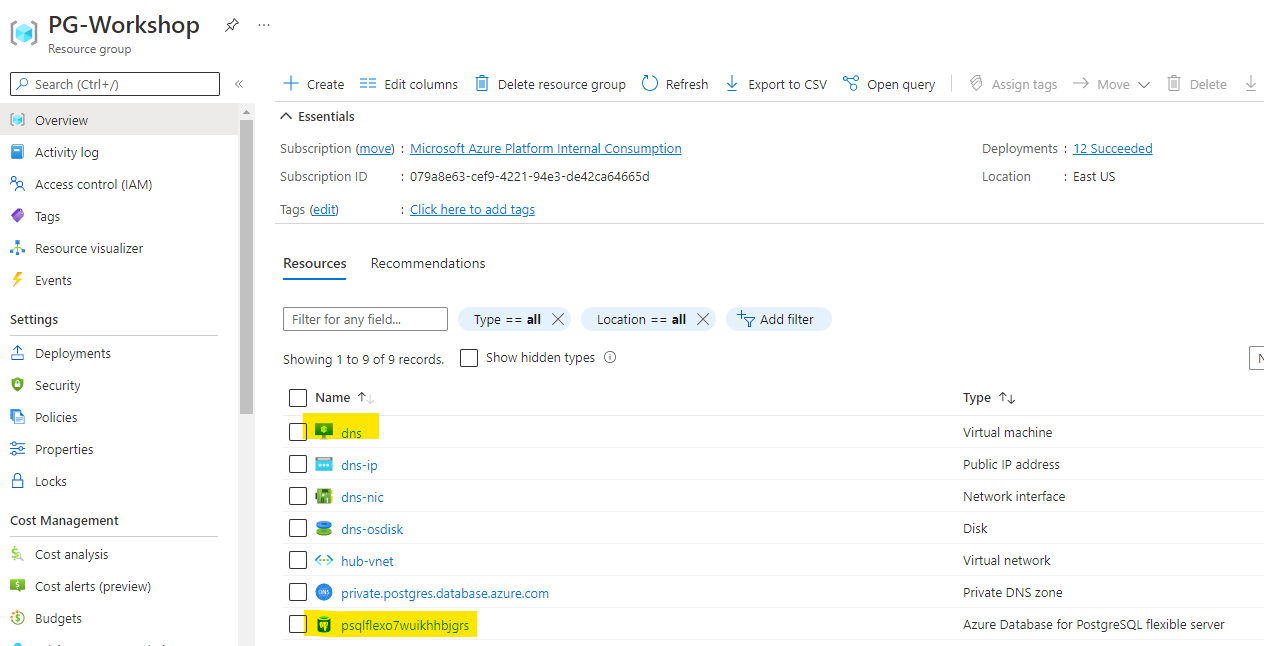
Visit both DNS VM to get the public IP and the PostgreSQL Flexible Server to get the access endpoint, please keep them as we will use them during the workshop.
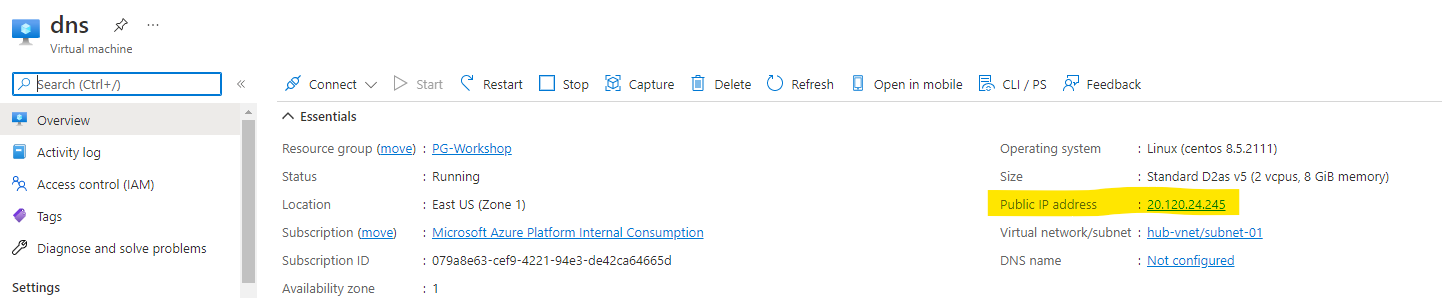
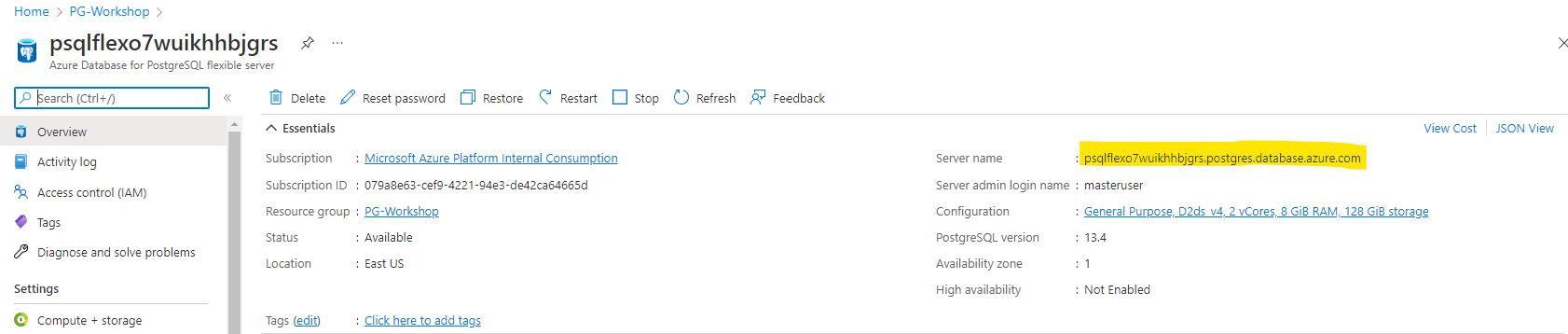
Now we move the next section to connect to the DB.
Connecting to PostgreSQL
In order to connect to a database you need to know the name of your target database, the host name and port number of the server, and what user name you want to connect as.
You can save yourself some typing by setting the environment variables PGDATABASE, PGHOST, PGPORT and/or PGUSER to appropriate values. It is also convenient to have a ~/.pgpass file to avoid regularly having to type in passwords.
Basic psql options
-d dbname
--dbname=dbname
Specifies the name of the database to connect to. This is equivalent to specifying dbname as the first non-option argument on the command line.
-h hostname
--host=hostname
Specifies the host name of the machine on which the server is running.
-p port
--port=port
Specifies the TCP port or the local Unix-domain socket file extension on which the server is listening for connections. Defaults to the value of the PGPORT environment variable or, if not set, to the port specified at compile time, usually **5432**.
-U username
--username=username
Connect to the database as the user username instead of the default. (You must have permission to do so, of course.)
-W
--password
Force psql to prompt for a password before connecting to a database.
Using Azure Cloud Shell
Example (please change these values to match with your setup) from the cloudshell
ssh username@<jumpbox-ip> # the DNS VM IP Address, and the username that you selected in deployment

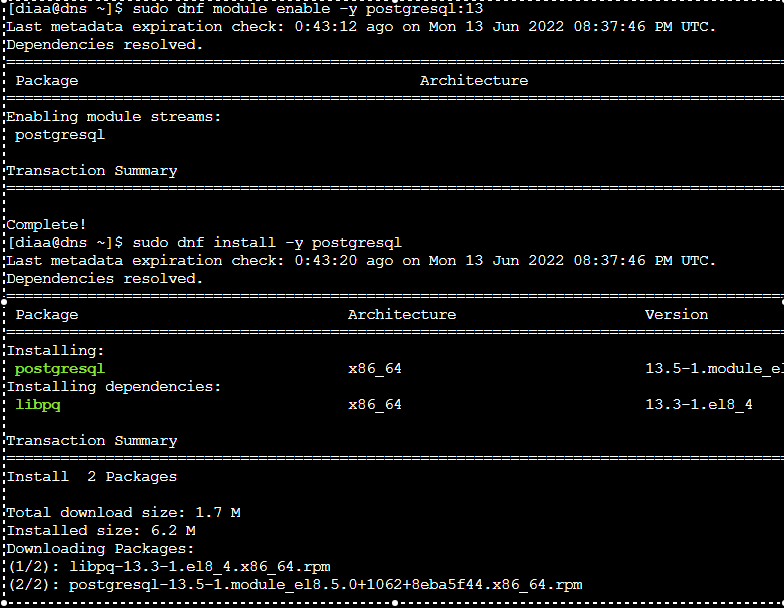
In the first time acessing the jumpbox make sure that you have psql installed use the following commands once you logon
sudo dnf module enable -y postgresql:13
sudo dnf install -y postgresql
You should see output like this
Then connect to the database
psql -U adminuser -h postgresql-db.postgres.database.azure.com postgres

Getting the connection string from Azure Portal
In this task, we will create a file in our Cloud Shell containing libpq environment variables that will be used to select default connection parameter values to PostgreSQL PaaS instance. These are useful to be able to connect to postgres in a fast and convenient way without hard-coding connection string.
Go to the “Connection Strings” tab on the left hand side of the Azure Portal and find psql connection string:
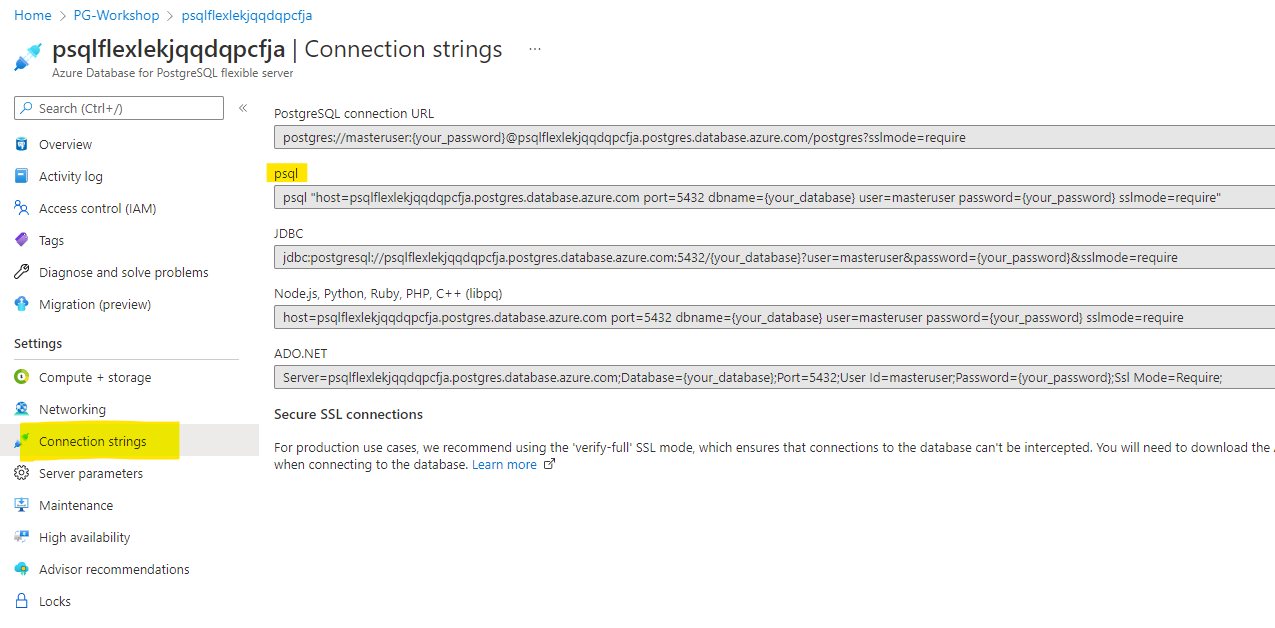
Open Cloud Shell and create a new .pg_azure file using your favourite editor (if you are not comfortable with Vim you can use VSCode):
Using VIM
vi .pg_azure
Add the following parameters or use the below wget command to download the file:
export PGDATABASE=postgres
export PGHOST=HOSTNAME.postgres.database.azure.com
export PGUSER=adminuser
export PGPASSWORD=your_password
export PGSSLMODE=require
Using Wget
wget https://pg.azure-workshops.cloud/scripts/pg_azure -O .pg_azure
Read the content of the file in the current session:
source .pg_azure
If you closed this bash session, you won’t be able to login again to psql without reading .pg_azure.
Let’s connect to our Azure database with psql client:
psql
You should connect to the postgres without any parameters
Task Hints You can also use the connection string shown in the Azure Portal in the Connection String tab. Using libpq variables is another option to ease your work with Postgres.
While you have the psql connected to the database, let’s run some quries:
SELECT version();
You should be able to read the PostgreSQL version.
Create table with some random data:
DROP TABLE IF EXISTS random_data;
CREATE TABLE random_data AS
SELECT s AS first_column,
md5(random()::TEXT) AS second_column,
md5((random()/2)::TEXT) AS third_column
FROM generate_series(1,500000) s;
Let’s select some of the records that we generated:
SELECT * FROM random_data LIMIT 10;
SELECT count(*) FROM random_data;
Data import and environment preparation
psql is a terminal-based front-end to PostgreSQL. It enables you to type in queries interactively, issue them to PostgreSQL, and see the query results.
Anything you enter in psql that begins with an unquoted backslash (\) is a psql meta-command that is processed by psql itself.
These commands make psql more useful for administration or scripting. Meta-commands are often called slash or backslash commands. The format of a psql command is the backslash, followed immediately by a command verb, then any arguments. The arguments are separated from the command verb and each other by any number of whitespace characters.
List the databases in the cluster:
psql
postgres=> \l
List the databases in the cluster with their sizes:
postgres=> \l+
Copy and paste following statements:
CREATE DATABASE quiz;
\connect quiz
CREATE TABLE public.answers (
question_id serial NOT NULL,
answer text NOT NULL,
is_correct boolean NOT NULL DEFAULT FALSE
);
CREATE TABLE public.questions (
question_id integer NOT NULL,
question text NOT NULL
);
ALTER TABLE ONLY public.answers
ADD CONSTRAINT answers_pkey PRIMARY KEY (question_id, answer);
ALTER TABLE ONLY public.questions
ADD CONSTRAINT questions_pkey PRIMARY KEY (question_id);
ALTER TABLE ONLY public.answers
ADD CONSTRAINT question_id_answers_fk FOREIGN KEY (question_id) REFERENCES public.questions(question_id);
CREATE SCHEMA calc;
CREATE OR REPLACE FUNCTION calc.increment(i integer) RETURNS integer AS $$
BEGIN
RETURN i + 1;
END;
$$ LANGUAGE plpgsql;
CREATE VIEW calc.vista AS SELECT $$I'm in calc$$;
CREATE VIEW public.vista AS SELECT $$I'm in public$$;
INSERT INTO public.questions (question_id, question) VALUES (1, 'Jaki symbol chemiczny ma tlen?');
INSERT INTO public.answers (question_id, answer, is_correct) VALUES (1, 'Au', false);
INSERT INTO public.answers (question_id, answer, is_correct) VALUES (1, 'O', true);
INSERT INTO public.answers (question_id, answer, is_correct) VALUES (1, 'Oxy', false);
INSERT INTO public.answers (question_id, answer, is_correct) VALUES (1, 'Tl', false);
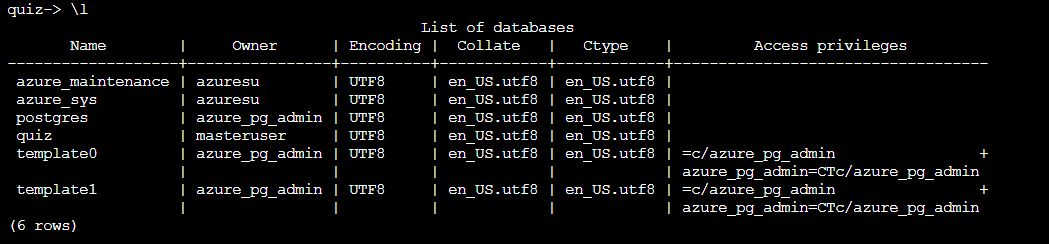
List the databases in the cluster:
postgres=> \l
Lists schemas (namespaces) in the current database:
quiz=> \dn
List of schemas
Name | Owner
--------+----------------
calc | masteruser
public | azure_pg_admin
(2 rows)
Check your current connection:
quiz=> \conninfo
You are connected to database "quiz" as user "masteruser" on host "psqlflexlekjqqdqpcfja.postgres.database.azure.com" (address "192.168.1.132") at port "5432".
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Check what’s going on in your instance:
quiz=> TABLE pg_stat_activity;
It’s unreadable, isn’t it? Change the display format:
quiz=> \x auto
And try to display the same view again:
quiz=> SELECT * FROM pg_stat_activity;
Display all relations (including tables, views, materialized views, indexes, sequences, or foreign tables) in your database:
quiz=> \d
List of relations
Schema | Name | Type | Owner
--------+-------------------------+----------+----------
public | answers | table | postgres
public | answers_question_id_seq | sequence | postgres
public | questions | table | postgres
public | vista | view | postgres
(4 rows)
Display all relations with their sizes and description:
quiz=> \d+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+-------------------------+----------+----------+------------+-------------
public | answers | table | postgres | 16 kB |
public | answers_question_id_seq | sequence | postgres | 8192 bytes |
public | questions | table | postgres | 16 kB |
public | vista | view | postgres | 0 bytes |
(4 rows)
Display information about one, specific table:
quiz=> \dt+ pg_class
Display tables, which names start with “pg_c[…]”
quiz=> \dt pg_c*
Check out help information:
quiz=> \?
Display the number of total connections to your database:
quiz=> SELECT count(*) FROM pg_stat_activity;
Watch the change of the count over time:
quiz=> \watch
Stop the process:
quiz=> [Ctrl+c]
List all system views:
quiz=> \dvS
Turns displaying of how long each SQL statement takes on:
quiz=> \timing
List the system functions:
quiz=> \dfS
Fetch and display the definition of the chosen function, in the form of a CREATE OR REPLACE FUNCTION command:
quiz=> \sf abs(bigint)
Print psql’s command line history:
quiz=> \s
Search for a specific command in the history:
quiz=> [Ctrl+r + part of the command string]
Basic PostgreSQL Administration
Managing PostgreSQL DB
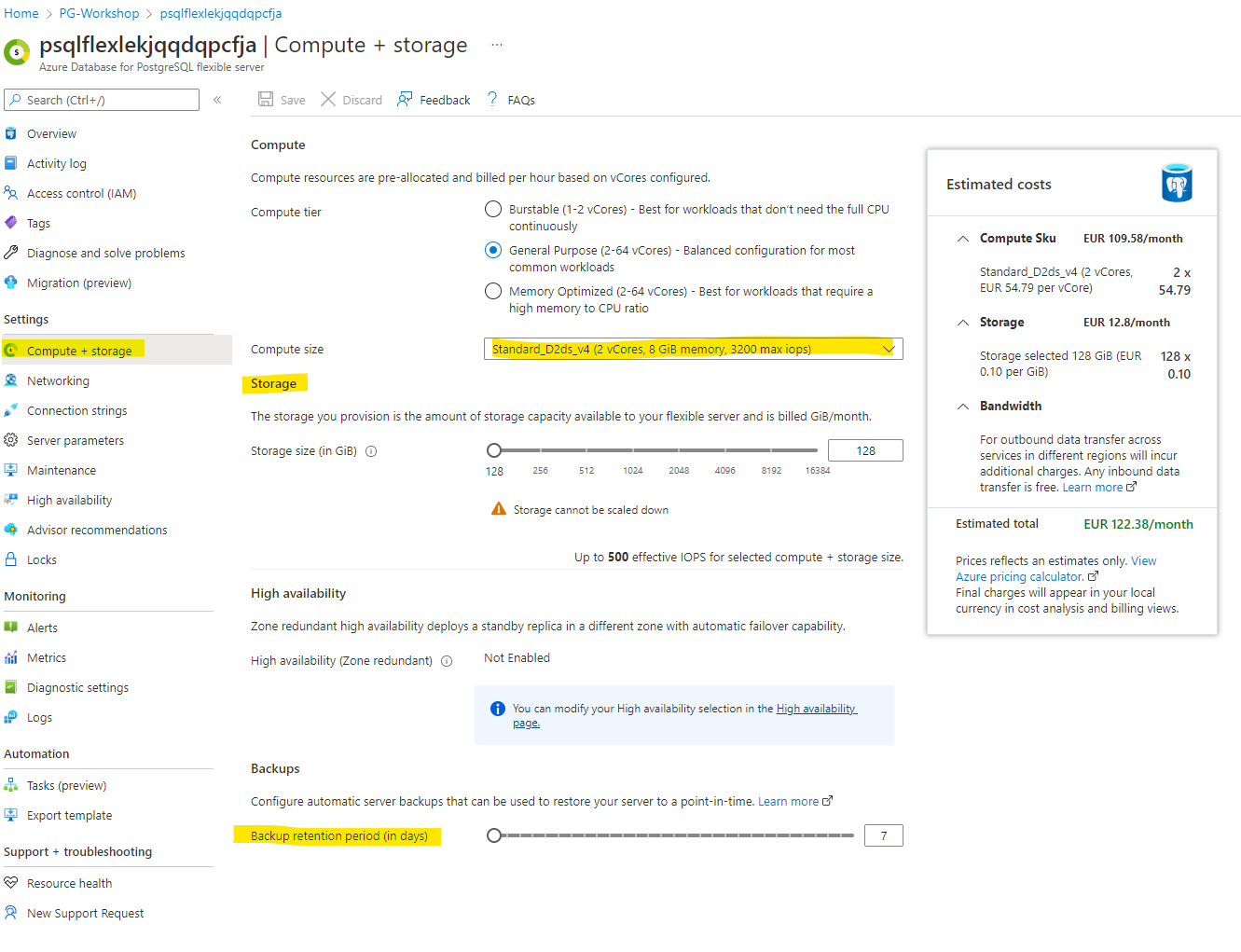
Managing Compute and Storage
Navigate to Compute + Storage, you will be able to alter storage and compute. Also, navigate to change the backup retention.
You don’t have to change the compute size as it might have additional cost for having a bigger instance.
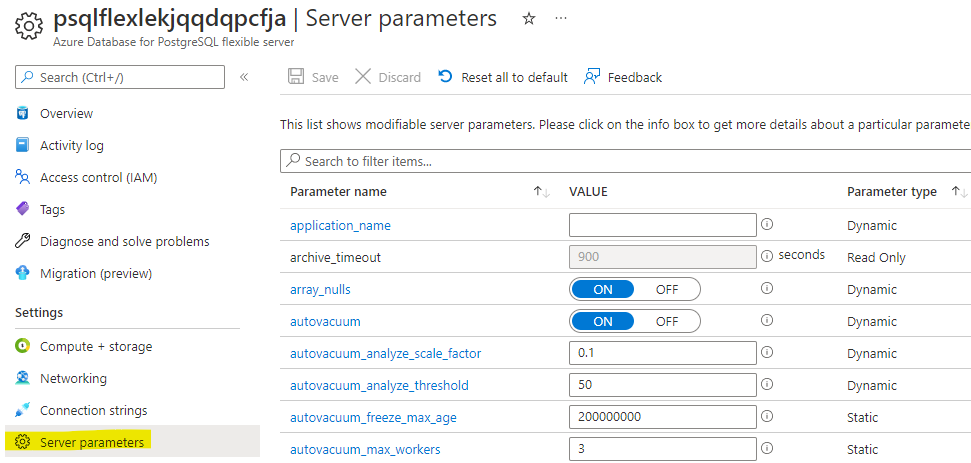
Managing Server Parameters
As you don’t have access to configuration files, you can change server parameters through the Azure Portal/APIs. All the changes made here provide default values for the entire cluster. Users can also make changes on the database level with ALTER DATABASE command, on the role level with ALTER ROLE command, or on the session level with the SET command.
In the search box type pgbouncer and change the value to TRUE:
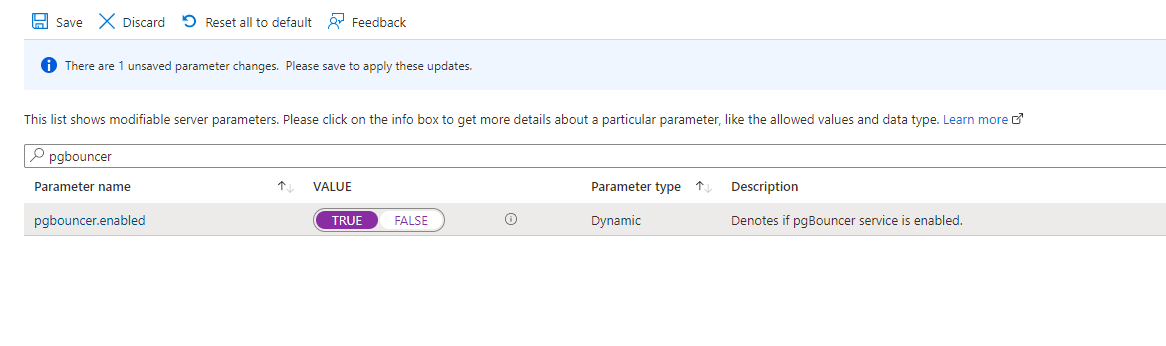
Save the changes, and wait until the new deployment finish successfully:
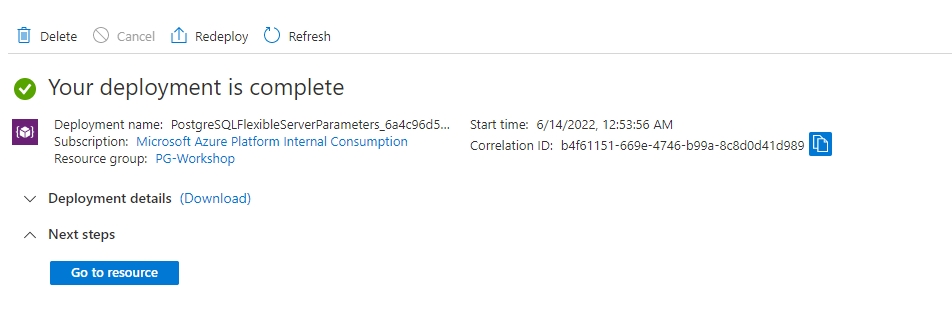
Once you see the success screen, go to the VM and try to access PostgreSQL through port 6432:
psql -p 6432

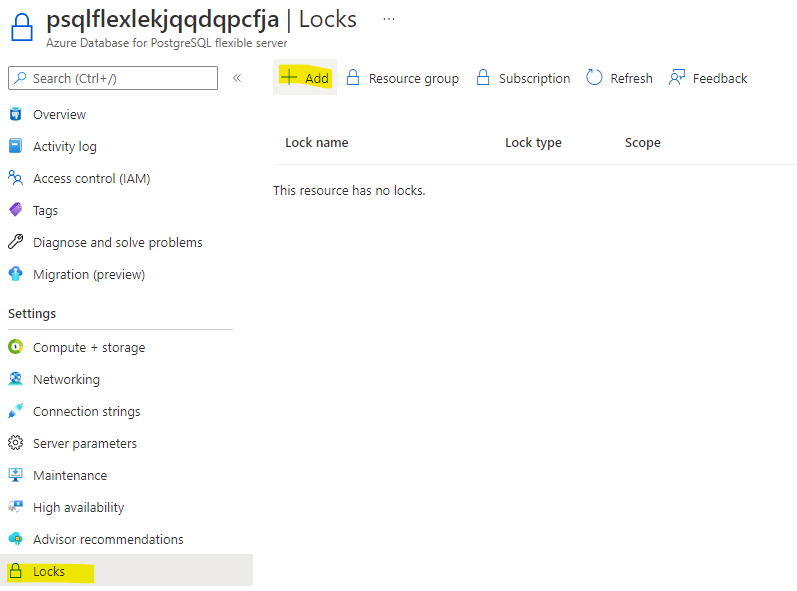
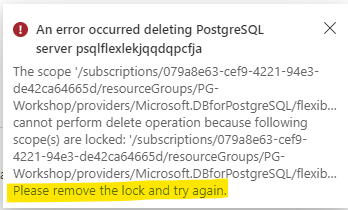
Apply Server Locks
Navigate to Locks:
Click on +Add, add Lock name of your choice and lock type with Delete:
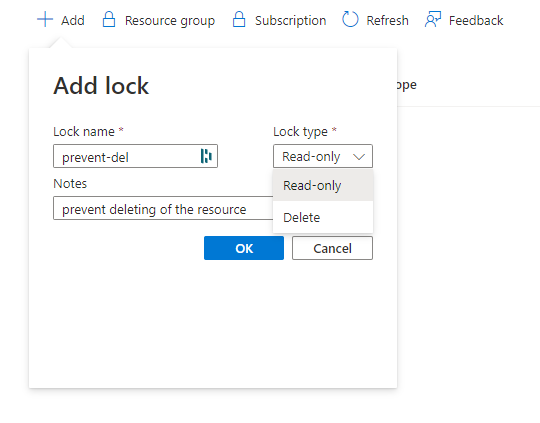
If you try to delete the server it should give the such below error:
Roles and Permissions
Connect to the PostgreSQL instance:
[diaa@dns ~]$ psql
psql (13.5, server 13.6)
SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=>
Create new group:
postgres=> CREATE GROUP monty_python;
Create a new user Graham that belongs to monty_python group and doesn’t inherit any privileges from the group. Allow the user to have maximum 2 active connection:
postgres=> CREATE USER Graham CONNECTION LIMIT 2 IN ROLE monty_python NOINHERIT;
Create a new user Eric that belongs to monty_python group and inherits privileges from the group. Allow the user to have maximum 2 active connections:
postgres=> CREATE USER Eric CONNECTION LIMIT 2 IN ROLE monty_python INHERIT;
Display all the roles available in the cluster:
postgres=> \dg
List of roles
Role name | Attributes | Member of
----------------+------------------------------------------------------------+----------------
eric | 2 connections | {monty_python}
graham | No inheritance +| {monty_python}
| 2 connections |
monty_python | Cannot login | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
Connect to the quiz database:
postgres=> \c quiz
Grant all privileges for all tables in schema public to group monty_python:
quiz=> GRANT ALL ON ALL TABLES IN SCHEMA public TO monty_python;
GRANT
In order to be able to switch to another role you need to grant this permission to the current user. Replace adminuser with your pg admin user name:
GRANT graham to adminuser;
GRANT eric to adminuser;
Switch to the Graham user:
quiz=> SET ROLE TO graham;
SET
Try to check the content of answers table as user Graham:
quiz=> TABLE answers;
ERROR: permission denied for table answers
Change the user and try to query the table again:
quiz=> SET ROLE TO eric;
SET
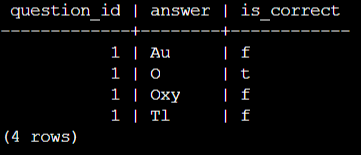
quiz=> table answers;
question_id | answer | is_correct
-------------+--------+------------
1 | Au | f
1 | O | t
1 | Oxy | f
1 | Tl | f
(4 rows)
Why user Graham doesn’t have permission to view the content of answer table?:
Changing permissions
Grant the SELECT privilege on table answers to user Graham:
quiz=> GRANT SELECT ON TABLE answers TO Graham;
WARNING: no privileges were granted for "answers"
GRANT
Switch back to the superuser account and try again:
quiz=> SET ROLE TO adminuser;
SET
quiz=> GRANT SELECT ON TABLE answers TO Graham;
GRANT
Check if user Graham is able to query the table:
quiz=> SET ROLE TO graham;
SET
quiz=> TABLE answers;
question_id | answer | is_correct
-------------+--------+------------
1 | Au | f
1 | O | t
1 | Oxy | f
1 | Tl | f
(4 rows)
Display all granted privileges:
quiz=> \dp
Access privileges
Schema | Name | Type | Access privileges | Column privileges | Policies
--------+-----------+-------+-------------------------------+-------------------+----------
public | answers | table | postgres=arwdDxt/postgres +| |
| | | monty_python=arwdDxt/postgres+| |
| | | graham=r/postgres | |
public | questions | table | postgres=arwdDxt/postgres +| |
| | | monty_python=arwdDxt/postgres | |
(2 rows)
Granting roles As user Graham try to DELETE all records from table answers:
quiz=> DELETE FROM answers ;
ERROR: permission denied for table answers
As adminuser copy all privileges from user eric to user graham:
quiz=> \c
You are now connected to database "quiz" as user "postgres".
quiz=> GRANT eric TO graham ;
GRANT ROLE
As user Graham try to DELETE all records from table answers:
quiz=> set role to graham;
SET
quiz=> DELETE FROM answers ;
ERROR: permission denied for table answers
quiz=> SET ROLE TO adminuser;
quiz=> GRANT DELETE ON TABLE answers TO graham;
GRANT
quiz=> SET role TO Graham;
SET
quiz=> DELETE FROM answers ;
Display permissions granted to objects and information about roles:
quiz=> \dp
Access privileges
Schema | Name | Type | Access privileges | Column privileges | Policies
--------+-----------+-------+-------------------------------+-------------------+---------
-
public | answers | table | postgres=arwdDxt/postgres +| |
| | | monty_python=arwdDxt/postgres+| |
| | | graham=r/postgres +| |
| | | eric=d/postgres | |
public | questions | table | postgres=arwdDxt/postgres +| |
| | | monty_python=arwdDxt/postgres | |
(2 rows)
quiz=> \dg
List of roles
Role name | Attributes | Member of
----------------+------------------------------------------------------------+---------------------
eric | 2 connections | {monty_python}
graham | No inheritance +| {monty_python,eric}
| 2 connections |
monty_python | Cannot login | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
Without INHERIT, membership in another role only grants the ability to SET ROLE to that other role; the privileges of the other role are only available after having done so.
Revoke DELETE privilege from eric:
quiz=> \c
You are now connected to database "quiz" as user "adminuser".
quiz=> REVOKE DELETE ON TABLE answers FROM eric;
REVOKE
quiz=> set role to eric;
SET
quiz=> delete from answers ;
DELETE 0
As you see user Eric is still able to perform DELETE operation because of his membership in role monty_python.
Accessibility and Business Continuity
Logical Backup
Plain pg_dump
Make sure you have sourced the file with libpq variables on your current session:
source .pg_azure
pg_dump like other native postgres utilities is able to use them to connect to your database instance.
Run pg_dump against quiz database:
pg_dump quiz
You can redirect the output of pg_dump to another program:
pg_dump quiz|less
Save the output of pg_dump:
pg_dump quiz > /tmp/quiz.plain.dump
Check the content of file:
less /tmp/quiz.plain.dump
Dump only the schema (without any data):
pg_dump --schema-only quiz > /tmp/quiz_ddl.plain.dump
Check the content of file:
less /tmp/quiz_ddl.plain.dump
You don’t have to each time specify the database name, you can for instance overwrite PGDATABASE variable just for this session:
export PGDATABASE=quiz
Let’s dump only the data:
pg_dump --data-only > /tmp/quiz_data.plain.dump
Check the content of file:
less /tmp/quiz_data.plain.dump
Change the COPY command to INSERT:
pg_dump --data-only --inserts > /tmp/quiz_data_insert.plain.dump
Check the content of file:
less /tmp/quiz_data_insert.plain.dump
Dump only one table:
pg_dump --table=answers > /tmp/answers.plain.dump
Check the content of file:
less /tmp/answers.plain.dump
Check all the options for pg_dump:
pg_dump --help
Restore from plain dump
Drop database quiz:
dropdb quiz
Recreate it:
createdb quiz
Restore it from your dump:
psql -f /tmp/quiz.plain.dump
Watch out for errors! You might want to redirect errors to a separate file:
psql -f /tmp/quiz.plain.dump 2> errors.txt
less errors.txt
Log in to psql and check if everything was properly restored.
Directory format
Create dump using directory format. That is the only format where you can many parallel jobs to dump your database.
pg_dump quiz -Fd -f /tmp/directorydump
Check the content of files in the directory:
zless /tmp/directorydump/*dat.gz
Restore from directory format dump
Drop database quiz:
dropdb quiz
Recreate it:
createdb quiz
Restore it from your dump:
pg_restore -d quiz /tmp/directorydump
Log in to psql and check if everything was properly restored.
Global objects dump
Dump logically the whole instance:
pg_dumpall > /tmp/whole_cluster.plain.dump
less /tmp/whole_cluster.plain.dump
Dump only the global objects:
pg_dumpall -g > /tmp/globals.plain.dump
less /tmp/globals.plain.dump
You will encounter errors because you don’t have access to export the passwords, if you run the following command you won’t see the errors:
pg_dumpall -g --no-role-passwords > /tmp/globals.plain.dump
Physical Backup and Point in Time Restore
Backup
While creating a server through the Azure portal, the Compute tier tab is where you select either Burstable **, **“General purpose” or Memory Optimized backups for your server. This window is also where you select the Backup Retention Period - how long (in number of days) you want the server backups stored for.
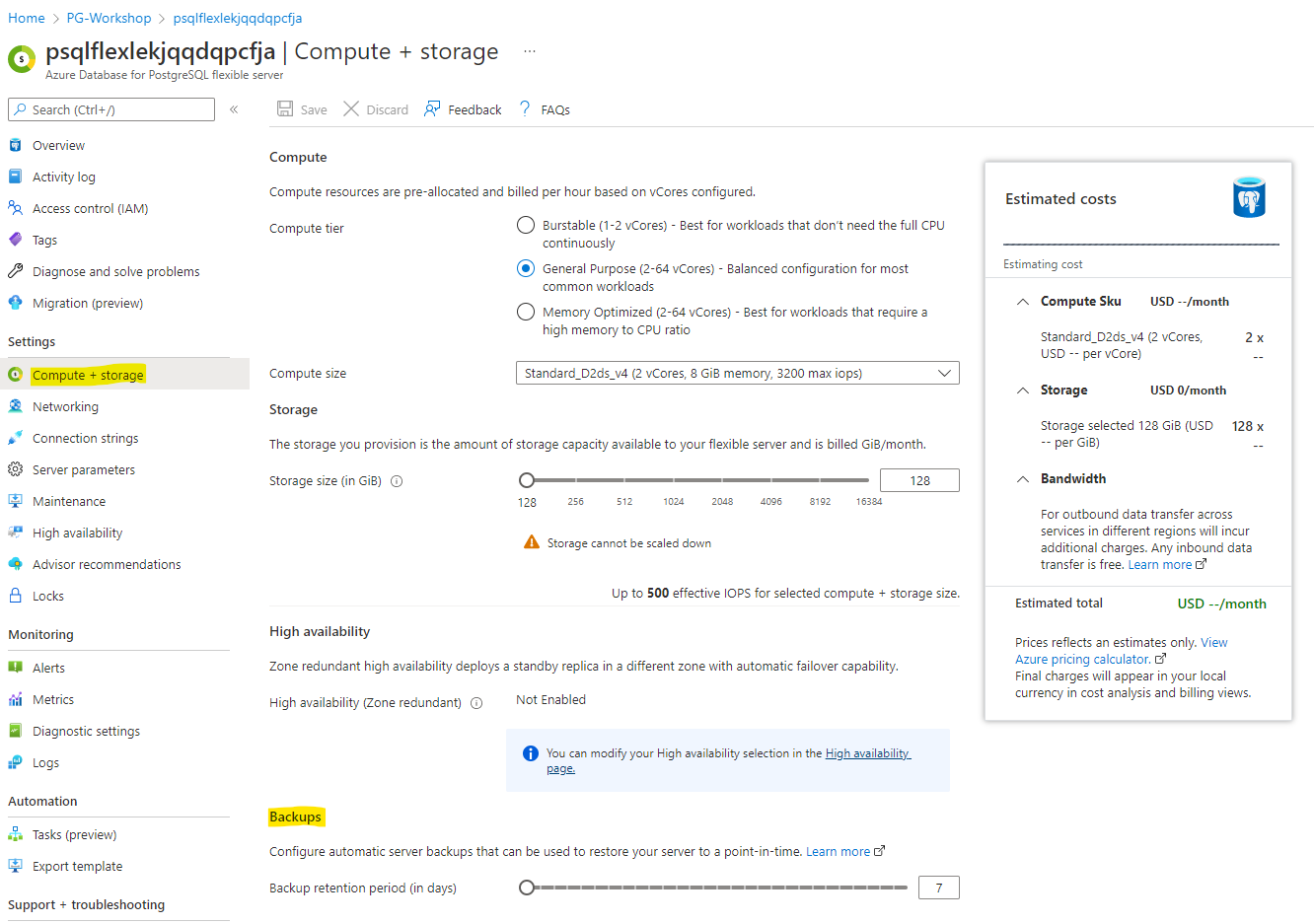
The backup retention period governs how far back in time a point-in-time restore can be retrieved, since it’s based on backups available. Point-in-time restore is described further in the following section.
After changing the retention period make sure to click Save
When you see the deployment finished, it means that retention period has changed
Point-in-time restore
Azure Database for PostgreSQL Flexible server allows you to restore the server back to a point-in-time and into to a new copy of the server. You can use this new server to recover your data, or have your client applications point to this new server.
For example, if a table was accidentally dropped at noon today, you could restore to the time just before noon and retrieve the missing table and data from that new copy of the server. Point-in-time restore is at the server level, not at the database level.
The following steps restore the sample server to a point-in-time:
-
In the Azure portal, select your Azure Database for PostgreSQL Flexible server.
-
In the toolbar of the server’s Overview page, select Restore.

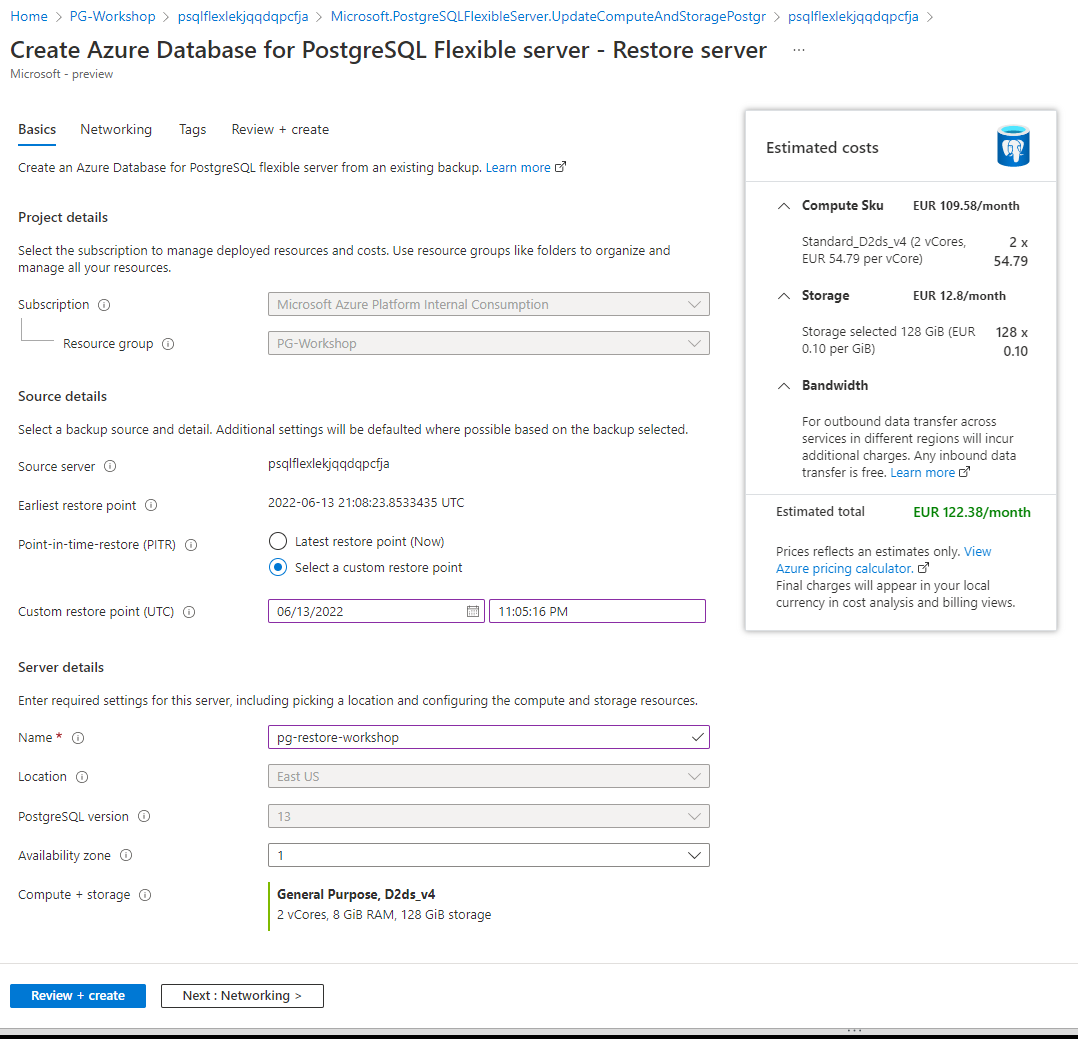
The new server created by point-in-time restore has the same server admin login name and password that was valid for the existing server at the point-in-time chose. You can change the password from the new server’s Overview page.
The new server created during a restore does not have the firewall rules or VNet service endpoints that existed on the original server. These rules need to be set up separately for this new server.
Database replication
Native logical replication
Logical replication uses the terms ‘publisher’ and ‘subscriber’.
- The publisher is the PostgreSQL database you’re sending data from.
- The subscriber is the PostgreSQL database you’re sending data to.
On the CloudShell run the following command to create new flexible server
az postgres flexible-server create --vnet spoke-vnet --subnet subnet-02 --resource-group PG-Workshop \
--name replication-flex-$$ --admin-user replica --admin-password 'PkG3zk&SKt' \
--sku-name Standard_B1ms --tier Burstable --storage-size 128 \
--tags "key=replica" --version 13 --high-availability Disabled

While the the the replication server being deployed, you can continue working on the primary database to change the parameters:
- Go to server parameters page on the portal.
- Set the server parameter wal_level to logical.
- Update max_worker_processes parameter value to at least 16. Otherwise, you may run into issues like WARNING: out of background worker slots.
- Save the changes and restart the server to apply the wal_level change.
- Confirm that your PostgreSQL instance allows network traffic from your connecting resource.
- Grant the admin user replication permissions.
ALTER ROLE <adminname> WITH REPLICATION;
The adminname is the PostgreSQL user that we used while creating the database in first section.
While on the primary database, we should create the publication
\c quiz
CREATE PUBLICATION answers_pub FOR TABLE answers;
Now. we can check if the database replica has finished, the output should be like the following the picture,
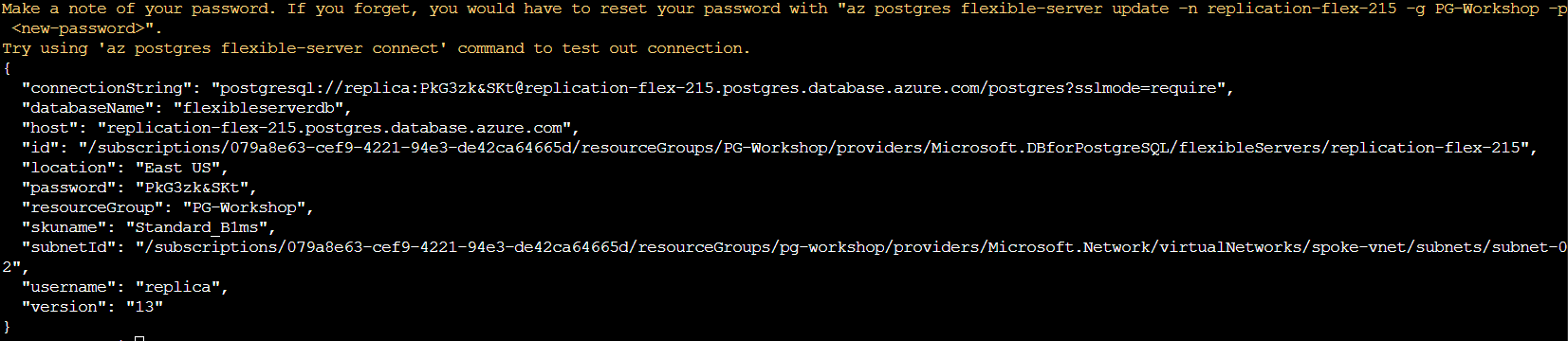
Once the replica server deployed, we need to change the Private DNS to private.postgresql.database.azure.com
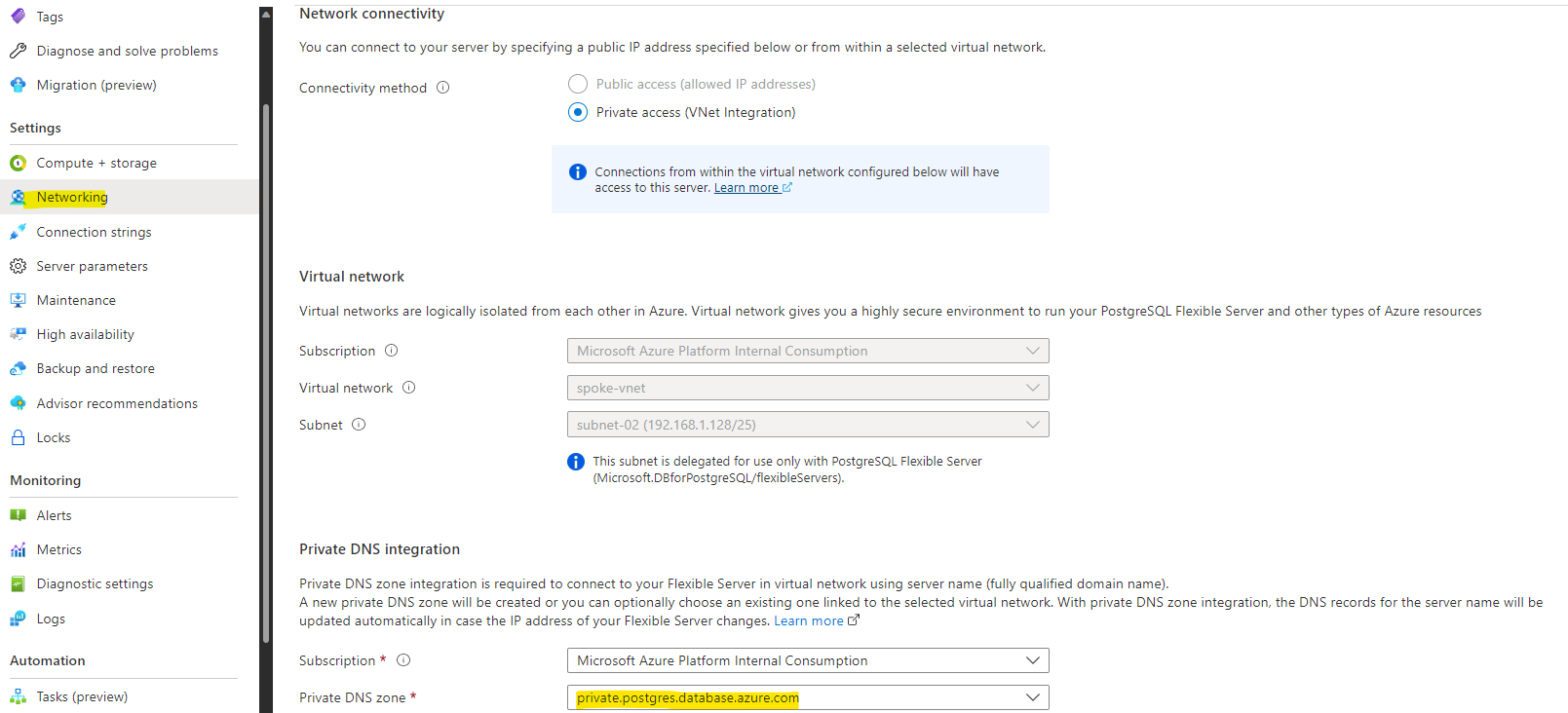
Notice the name of the PostgreSQL name it should be “replication-flex-<Random Number>.postgres.database.azure.com”
Log in to the Jump-box (DNS) and access the new created database (change 123 to match with your number):
export PGPASSWORD='PkG3zk&SKt'; psql -d postgres -U replica -h replication-flex-<123>>.postgres.database.azure.com

Once connected, create the DDL of the database:
CREATE DATABASE quiz;
\connect quiz
CREATE TABLE public.answers (
question_id serial NOT NULL,
answer text NOT NULL,
is_correct boolean NOT NULL DEFAULT FALSE
);
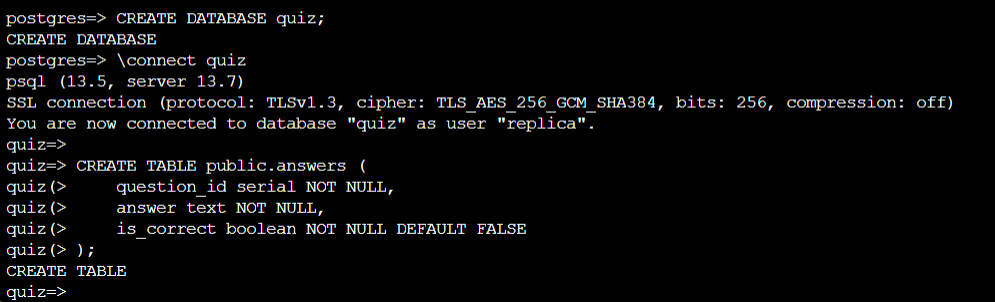
Now, we want to create the connection, make sure that you change the parameters to match your environment.
CREATE SUBSCRIPTION sub CONNECTION 'host=192.168.1.132 user=diaa dbname=quiz password=@n6DnfN&P' PUBLICATION answers_pub;
Check the answers table, the table shouldn’t be 0 rows :
table answers;
HA/DR
High Availability
Azure Database for PostgreSQL - Flexible Server offers high availability configuration with automatic failover capability using zone redundant server deployment. When deployed in a zone redundant configuration, flexible server automatically provisions and manages a standby replica in a different availability zone. Using PostgreSQL streaming replication, the data is replicated to the standby replica server in synchronous mode.
Tasks
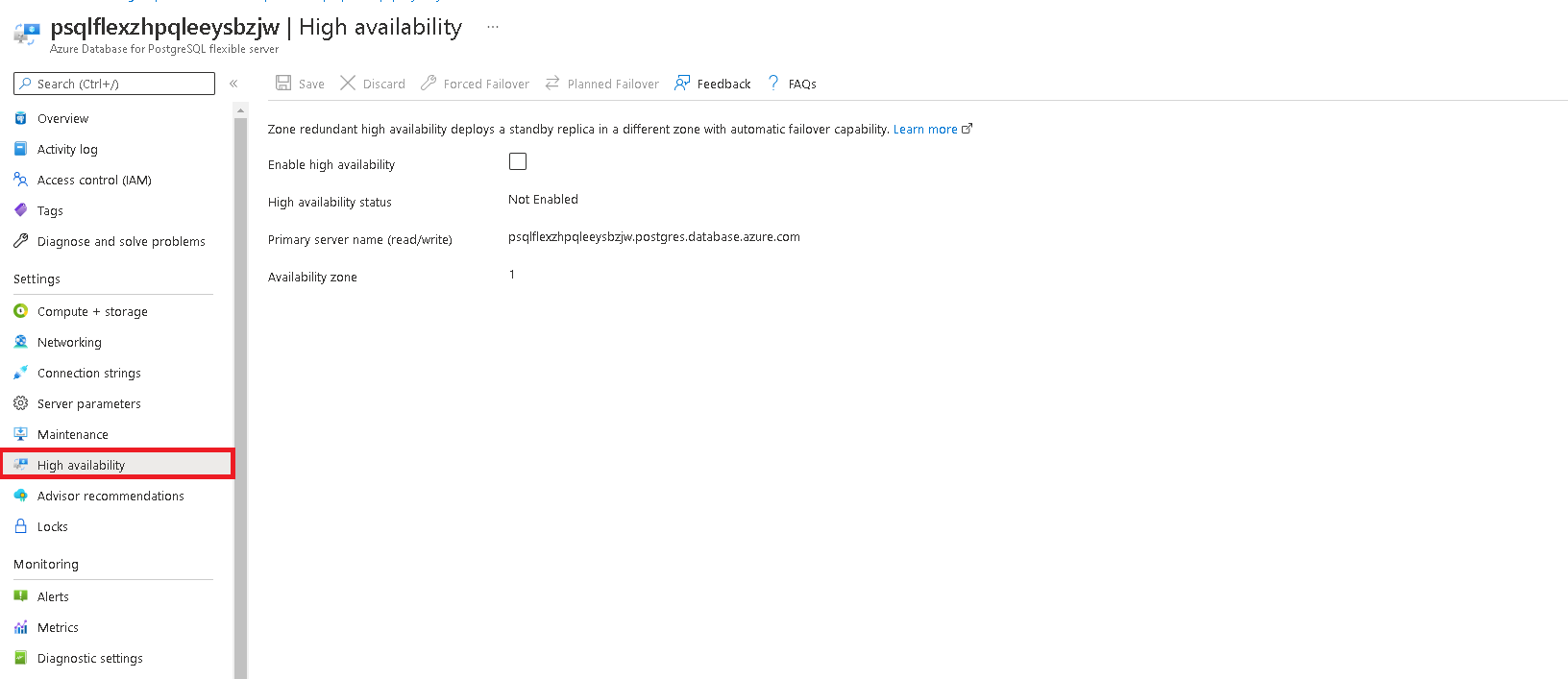
- Configure Azure Database for PostgreSQL - Flexible Server for High Availability
Click the high availability tab to configure high availability.
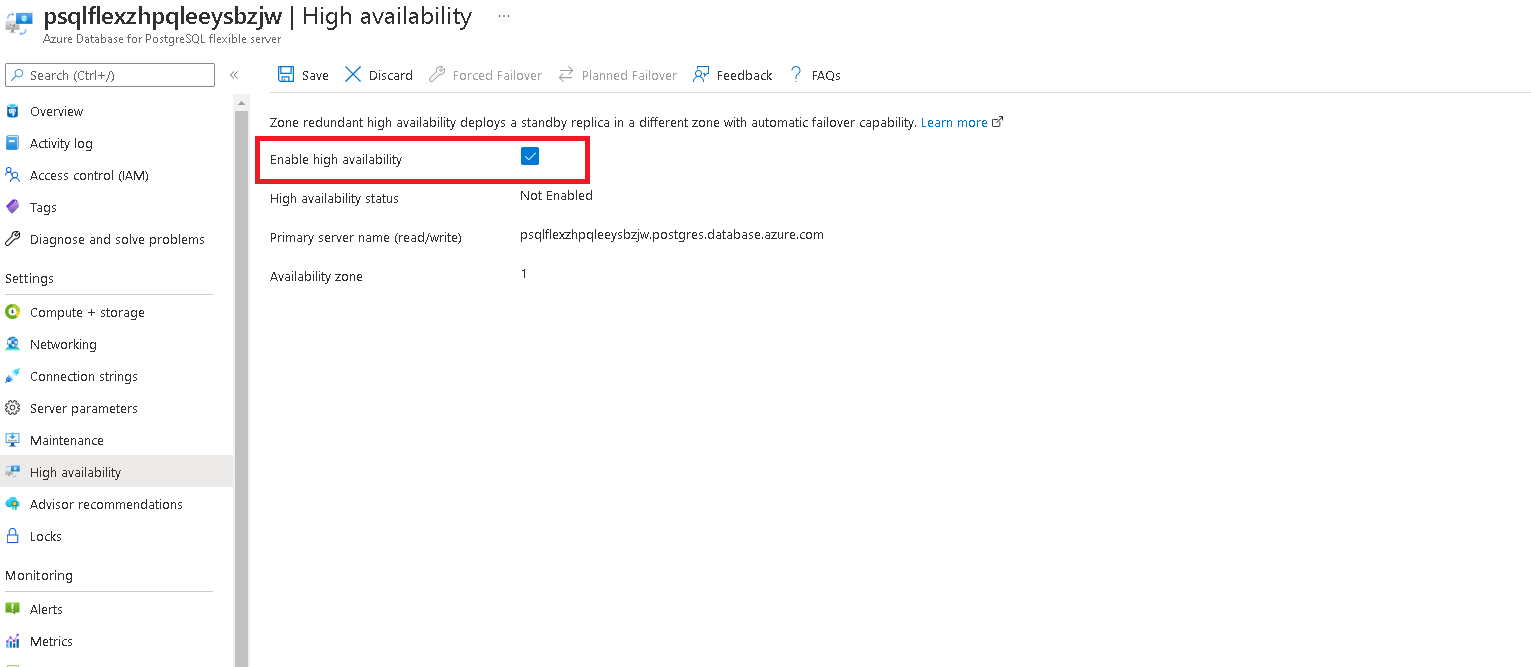
Ensure to check the box and save your changes. This will trigger a high availability deployment.
You will see a confirmation pop up, click yes.
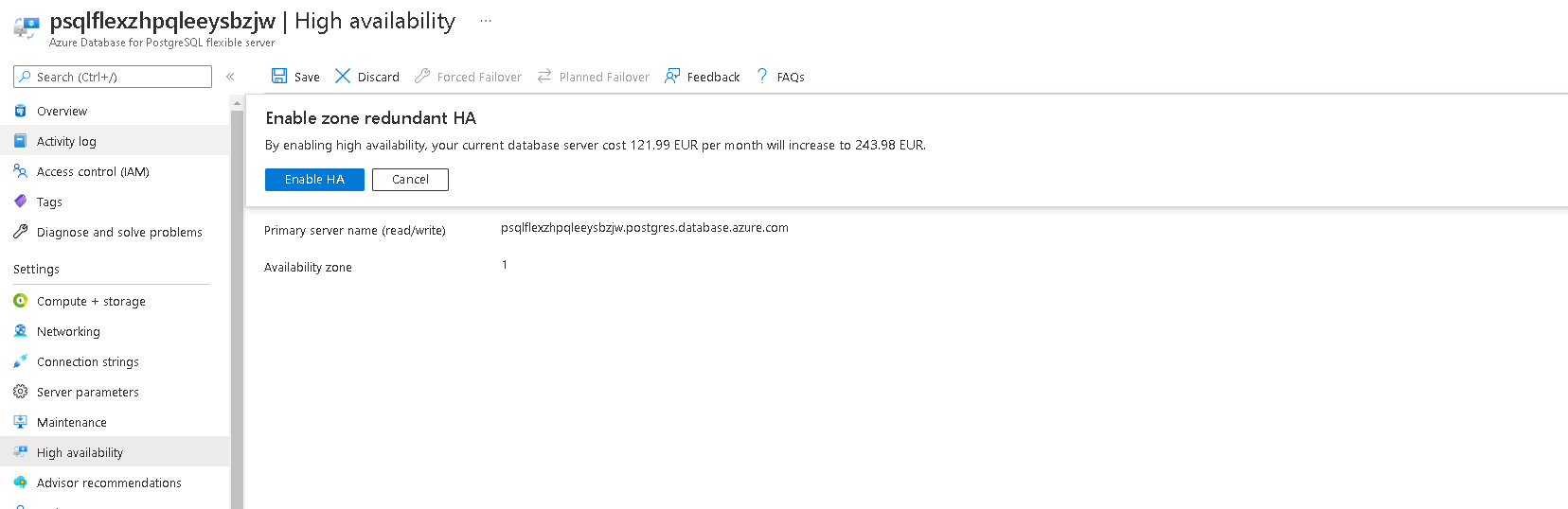
You will reveive a message like this once deployment is complete.
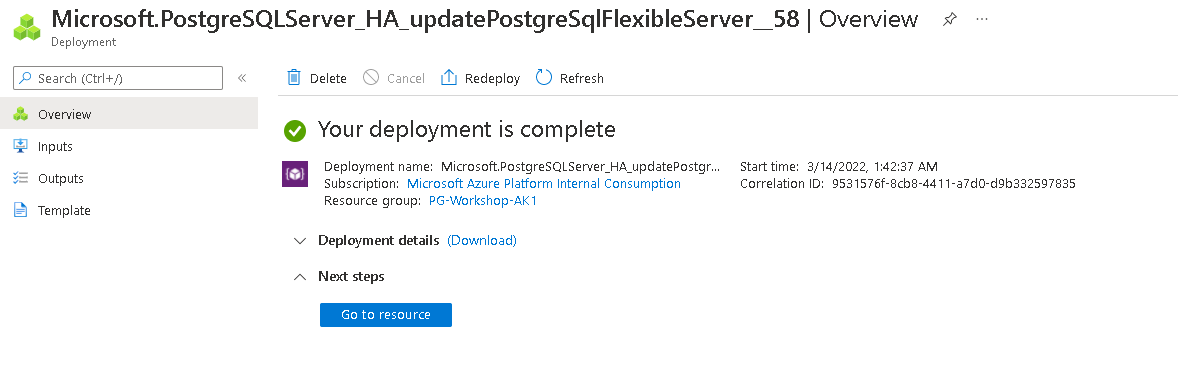
- Execute a Forced Failover
From Azure portal, click on the forced failover button to initiate a forced failover to secondary.

You will see a message like this once failover is complete.
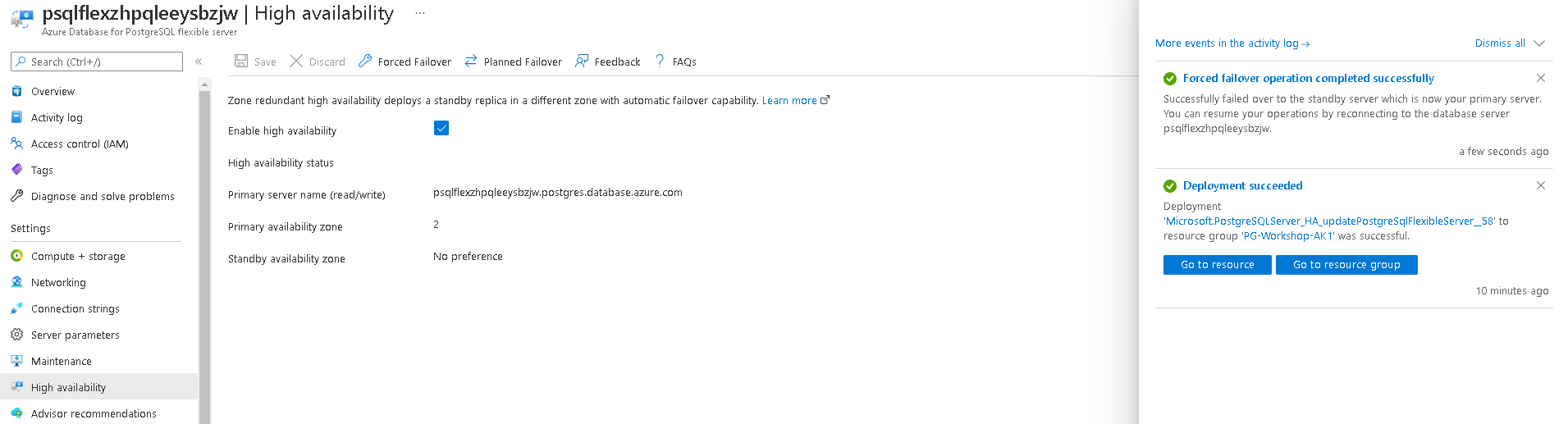
Once the process is complete, check if the primary and secondary zones have interchanged.
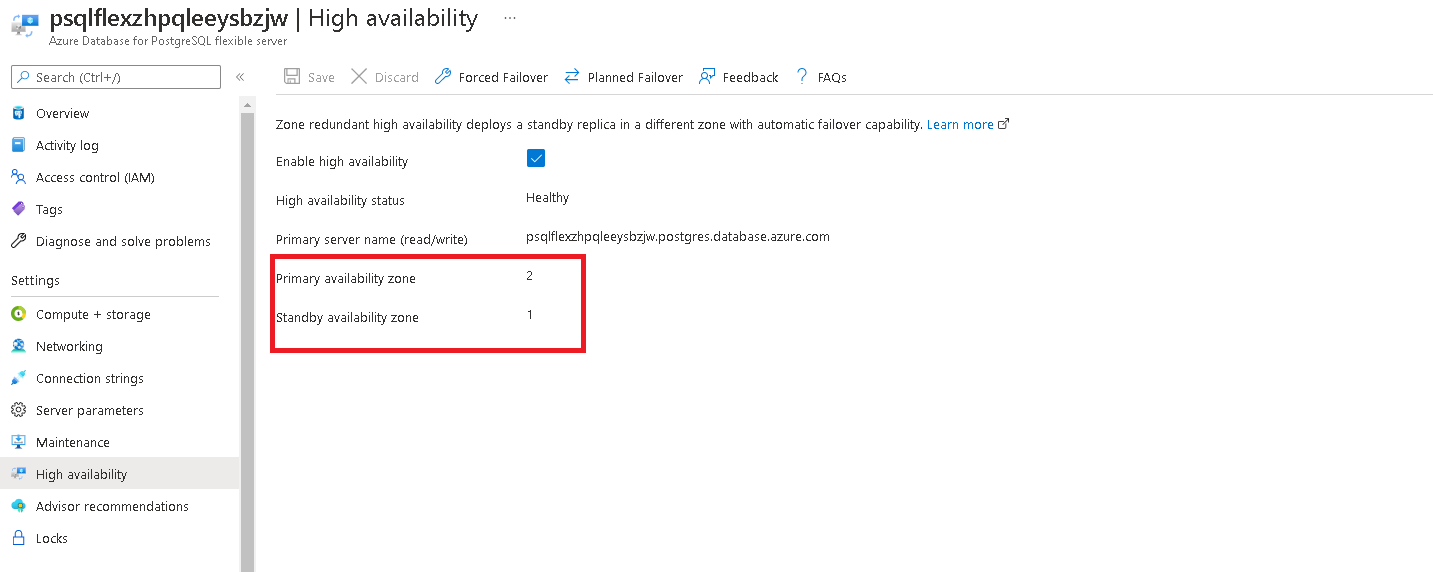
- Execute a planned failover
From Azure portal, click on the planned failover button to initiate a planned failover to secondary.
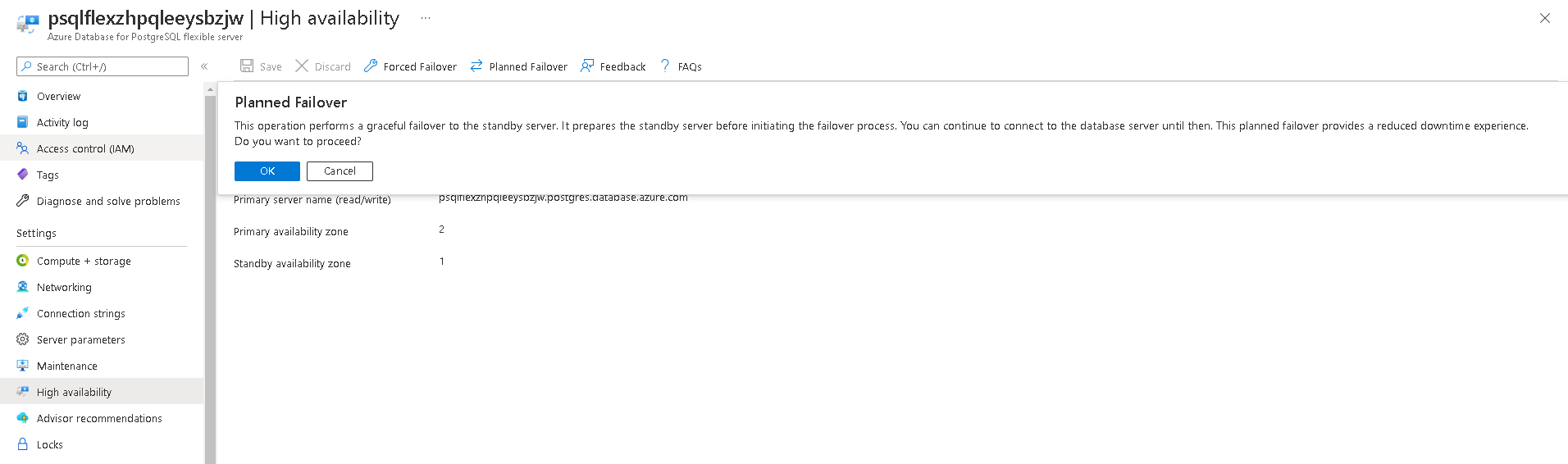
You will see a message like this once failover is complete.
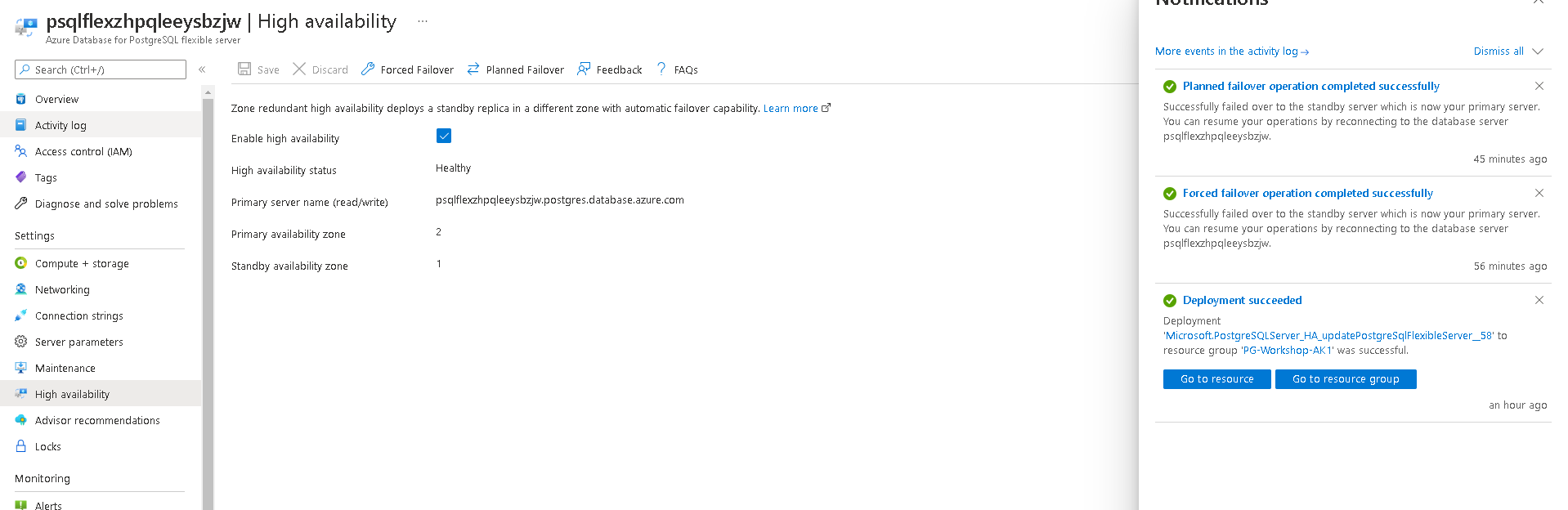
- Disable High Availability
To disable high available, navigate to high availablity tab.
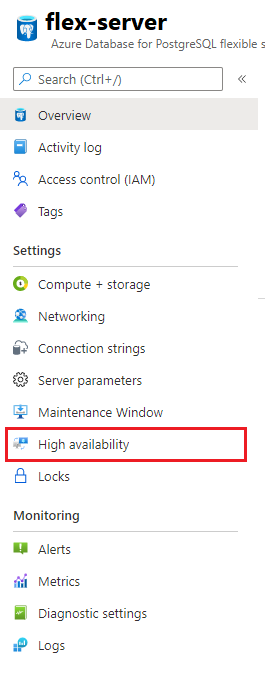
Uncheck the availability option and click save.
Azure Backup
Backup and restore in Azure Database for PostgreSQL - Flexible Server
Azure Database for PostgreSQL - Flexible Server automatically performs regular backups of your server. You can then do a point-in-time recovery (PITR) as seen in the previous section, within a retention period that you specify.
Tasks:
- Manual backup: Backing up database
You can manually take a backup by using the PostgreSQL tool pg_dump and pg_restore.
SSH into to the jumpbox vm.
ssh username@<jumpbox-ip
Execute below command to take a back up of the database.
pg_dump -Fc -v --host=<host> --username=<name> --dbname=<database name> -f <database>.dump
- Restore manual dabase backup using pg_restore
pg_restore -v --no-owner --host=<server name> --port=<port> --username=<user-name> --dbname=<target database name> <database>.dump
You can read how to optimize the migration process here
Patching and maintenance windows
Scheduled maintenance in Azure Database for PostgreSQL – Flexible server
Azure Database for PostgreSQL - Flexible server performs periodic maintenance to keep your managed database secure, stable, and up-to-date. During maintenance, the server gets new features, updates, and patches. You can configure custom maintenance schedules for your server.
Tasks:
- Selecting a custom maintenance window
Navigate to the maintenance tab in Azure portal for your flexible server.
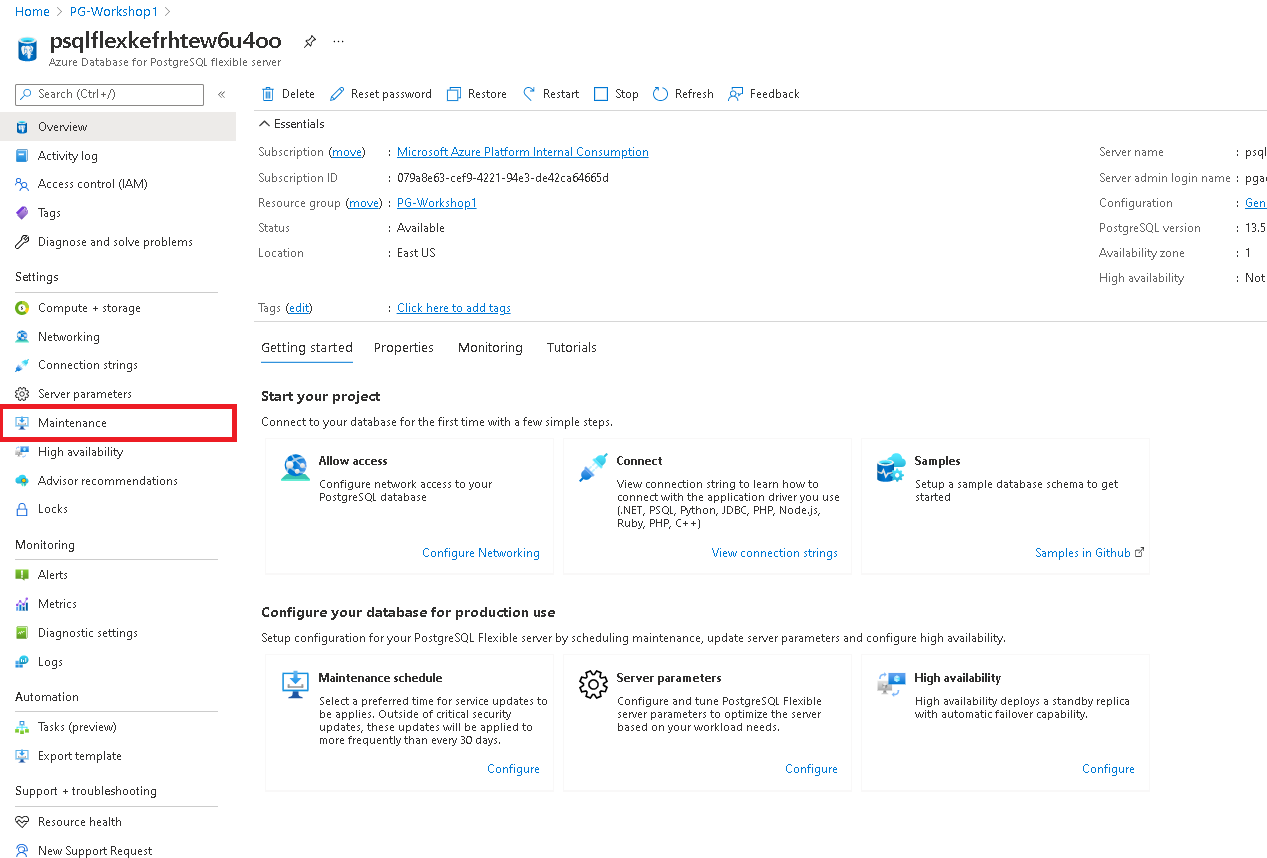
Select a custom schedule from the options available in the drop down.
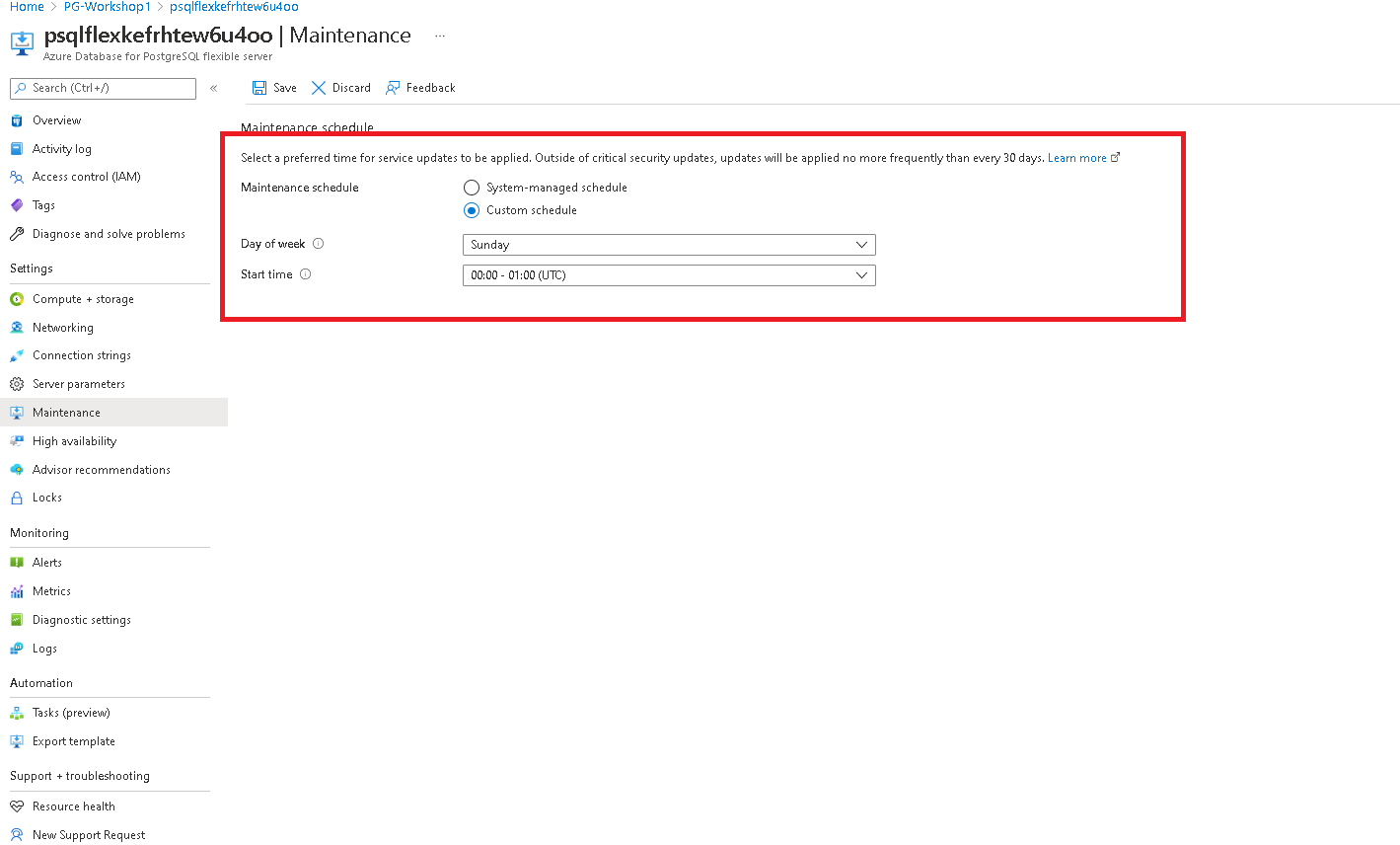
Click on save schedule to complete the configuration.
Security Management PostgreSQL
Installing pgAudit extension
Audit logging of database activities in Azure Database for PostgreSQL - Flexible server is available through the PostgreSQL Audit extension: pgAudit. pgAudit provides detailed session and/or object audit logging. To enable pgAudit on Azure Database for PostgreSQL - Flexible Server please follow the steps below.
On the sidebar, select Server Parameters and type extension in the search field.
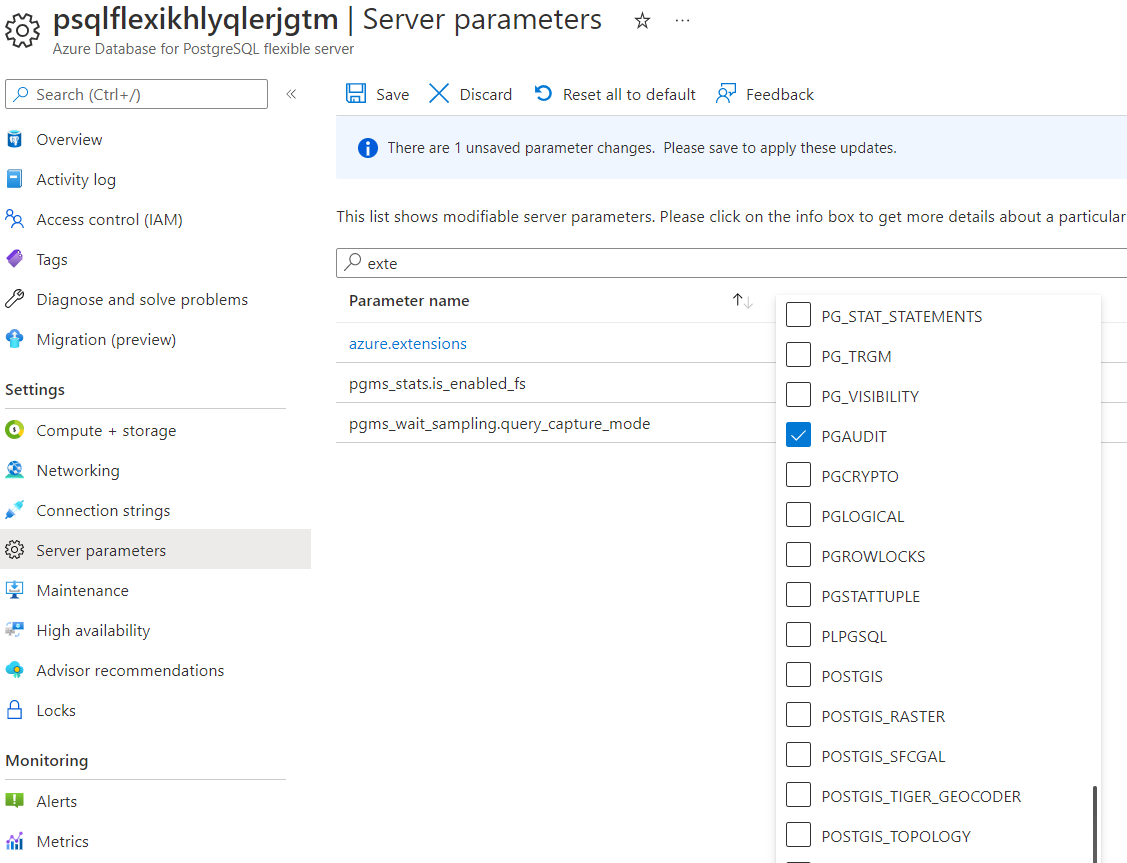
Hit Save
Once deployment is done go back to the Server Parameters and search for shared_preload_libraries and choose pgAudit.
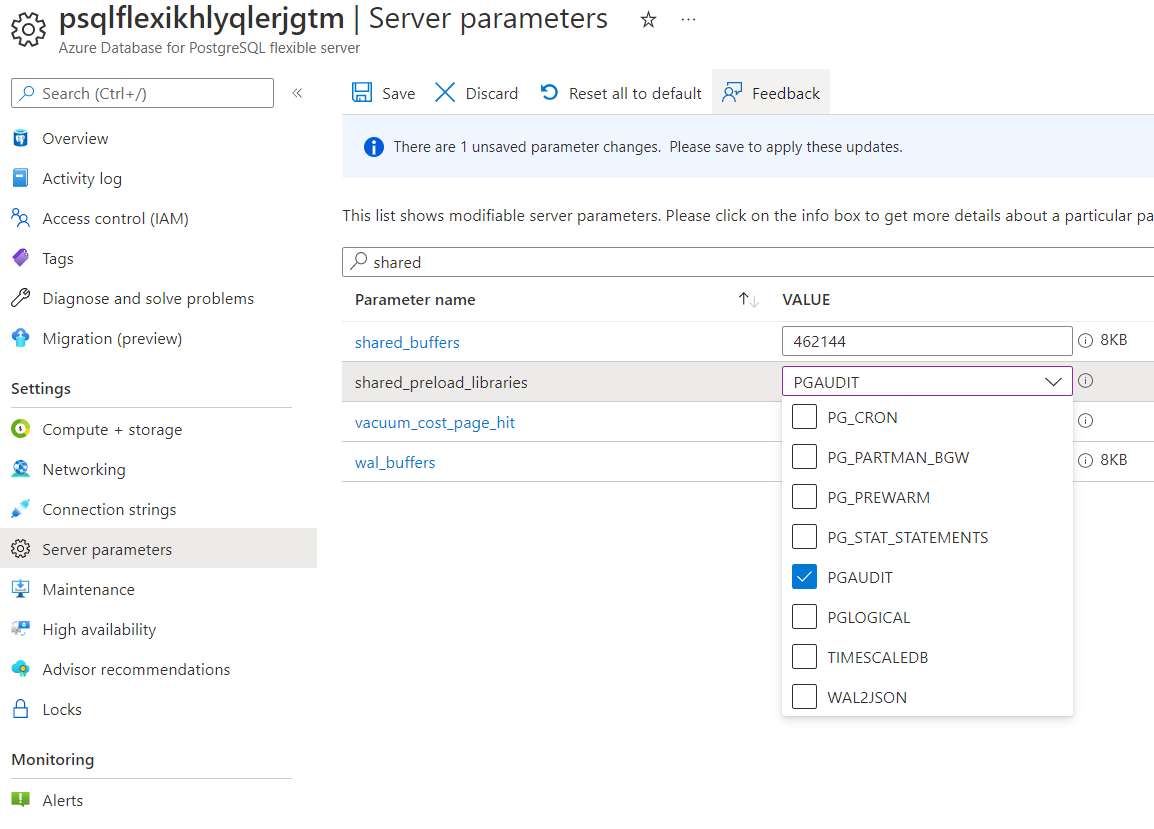
Hit Save and then choose Save and Restart.
At this point you have the extension installed and you can go ahead and CREATE EXTENSION is the database. Connect to your server using a client (like psql) and enable the pgAudit extension.
CREATE EXTENSION pgaudit;
Once you have enabled pgAudit, you can configure its parameters to start logging. To configure pgAudit you can follow below instructions. Using the Azure portal: On the sidebar, select Server Parameters and search for pgaudit. Change the pgaudit.log from NONE to ALL:
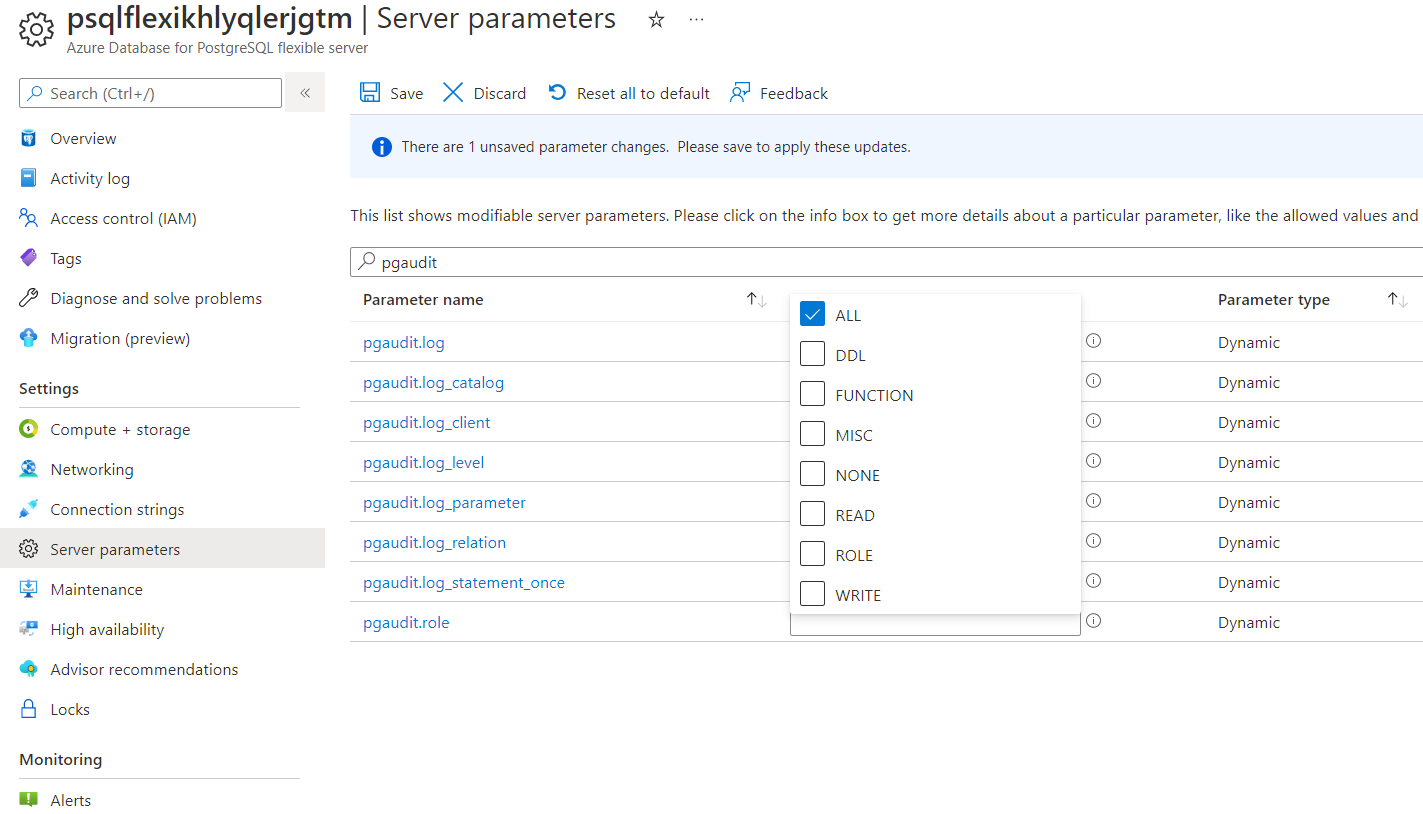
From now on all the actions in your database will be traced.
Viewing audit logs
The way you access the logs depends on which endpoint you choose. We have configured storage account and mounted it into the VM.
Open two cloud shell terminals, one will be needed to run some SQL commands (psql) and on the second we will observe log generation. From psql run some queries:
CREATE TABLE a(id int);
INSERT into a SELECT generate_series(1,1000);
From the second terminal configure a mounted container location so you can have the storage account mounted on your filesystem:
Mounting Storage Account to VM
In this section you will mount Storage Account to your dns VM to be able to easier manipulate on log files.
First let’s download and install necessary packages. Feel free to simply copy and paste the following commands:
sudo rpm -Uvh https://packages.microsoft.com/config/rhel/8/packages-microsoft-prod.rpm
sudo dnf -y install blobfuse
sudo mkdir /mnt/ramdisk
sudo mount -t tmpfs -o size=16g tmpfs /mnt/ramdisk
sudo mkdir /mnt/ramdisk/blobfusetmp
sudo chown <your VM admin> /mnt/ramdisk/blobfusetmp
Authorize access to your storage account
You can authorize access to your storage account by using the account access key, a shared access signature, a managed identity, or a service principal. Authorization information can be provided on the command line, in a config file, or in environment variables.
For this exercise we will authorize with the account access keys and storing them in a config file. The config file should have the following format:
accountName myaccount
accountKey storageaccesskey
containerName insights-logs-postgresqllogs
Please prepare the following file in editor of your choice. Values for the accountName and accountKey you will find in the Azure Portal. Please navigate to your storage account in the portal and then choose Access keys page:
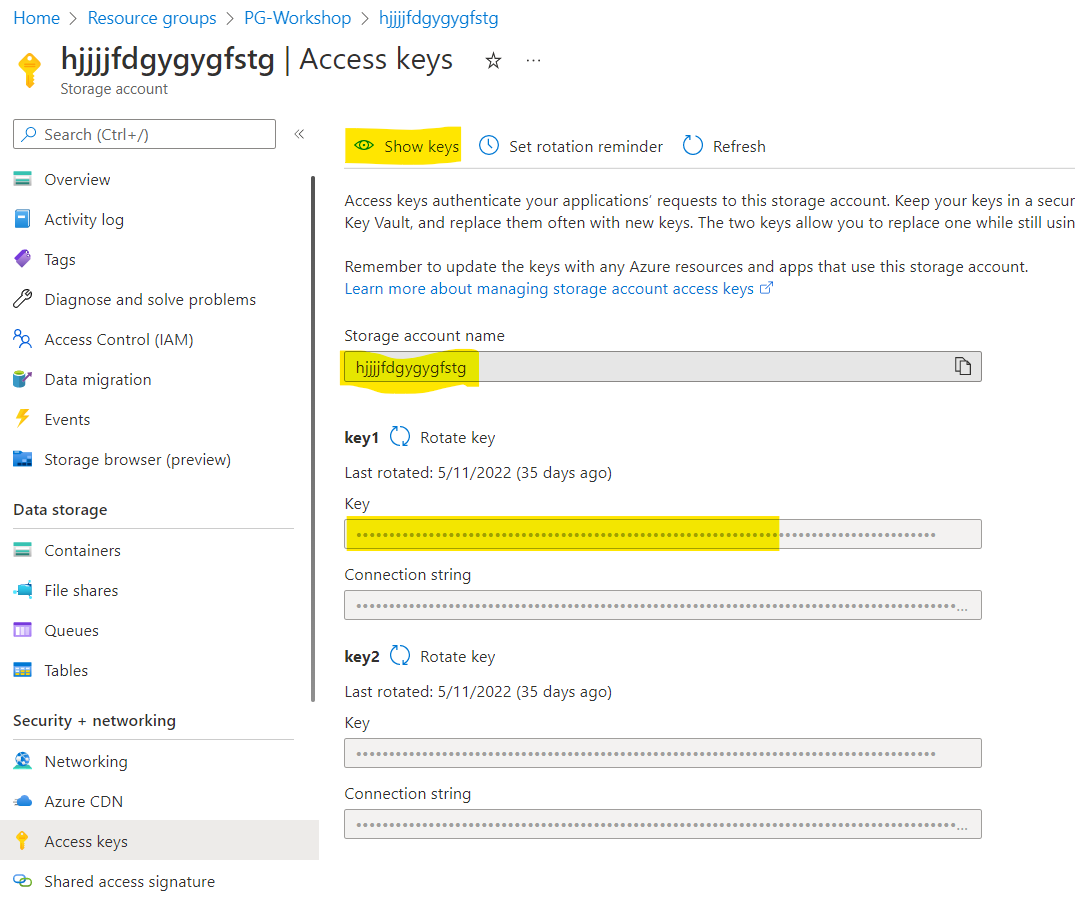
Copy accountName and accountKey and paste it to the file. Copy the content of your file and paste it to the fuse_connection.cfg file in your home directory, then mount your storage account container onto the directory in your VM:
vi fuse_connection.cfg
chmod 600 fuse_connection.cfg
mkdir ~/mycontainer
sudo blobfuse ~/mycontainer --tmp-path=/mnt/resource/blobfusetmp --config-file=/home/<your VM admin>/fuse_connection.cfg -o attr_timeout=240 -o entry_timeout=240 -o negative_timeout=120
sudo -i
cd /home/<your VM admin>/mycontainer/
ls # check if you see mounted container
# Please use tab key for directory autocompletion; do not copy and paste!
cd resourceId\=/SUBSCRIPTIONS/<your subscription id>/RESOURCEGROUPS/PG-WORKSHOP/PROVIDERS/MICROSOFT.DBFORPOSTGRESQL/FLEXIBLESERVERS/PSQLFLEXIKHLYQLERJGTM/y\=2022/m\=06/d\=16/h\=09/m\=00/
ls
less
and output appended data as the log file grows with the tail command:
tail -f
After a minute or two (please expect a slight delay) you will see your commands being registered by pgAudit. You should see the following lines:
{ "properties": {"timestamp": "2022-05-23 08:23:59.526 UTC","processId": 9300,"errorLevel": "LOG","sqlerrcode": "00000","message": "2022-05-23 08:23:59 UTC 9300 5-1 db-pgbench,user-pgadmin,app-psql,client-192.168.0.4 LOG: AUDIT: SESSION,1,1,DDL,CREATE TABLE,TABLE,public.a,CREATE TABLE a(id int);,<not logged>"}, "resourceId": "/SUBSCRIPTIONS/***/RESOURCEGROUPS/PG-WORKSHOP/PROVIDERS/MICROSOFT.DBFORPOSTGRESQL/FLEXIBLESERVERS/PSQLFLEXIKHLYQLERJGTM", "category": "PostgreSQLLogs", "operationName": "LogEvent"}
{ "properties": {"timestamp": "2022-05-23 08:24:00.511 UTC","processId": 9300,"errorLevel": "LOG","sqlerrcode": "00000","message": "2022-05-23 08:24:00 UTC 9300 9-1 db-pgbench,user-pgadmin,app-psql,client-192.168.0.4 LOG: AUDIT: SESSION,2,1,WRITE,INSERT,,,\"INSERT into a SELECT generate_series(1,1000);\",<not logged>"}, "resourceId": "/SUBSCRIPTIONS/***/RESOURCEGROUPS/PG-WORKSHOP/PROVIDERS/MICROSOFT.DBFORPOSTGRESQL/FLEXIBLESERVERS/PSQLFLEXIKHLYQLERJGTM", "category": "PostgreSQLLogs", "operationName": "LogEvent"}
Day Two Operations
Configure PgBadger
Configuring Server Parameters
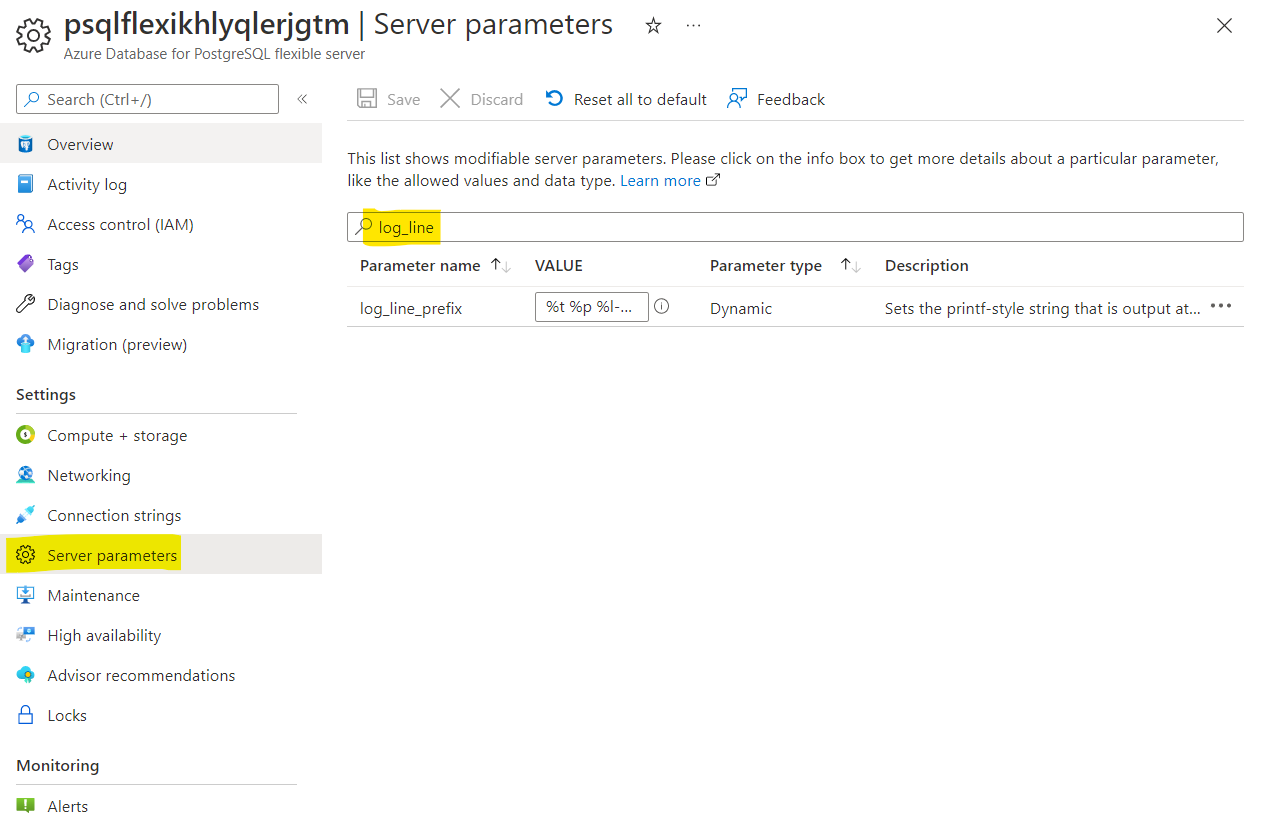
Navigate to Server Parameters page in the Azure Portal and modify the following parameters:
log_line_prefix = '%t %p %l-1 db-%d,user-%u,app-%a,client-%h ' #Please mind the space at the end!
log_lock_waits = on
log_temp_files = 0
log_autovacuum_min_duration = 0
log_min_duration_statement=0
You can type part of the name in the search field to find them quicker:
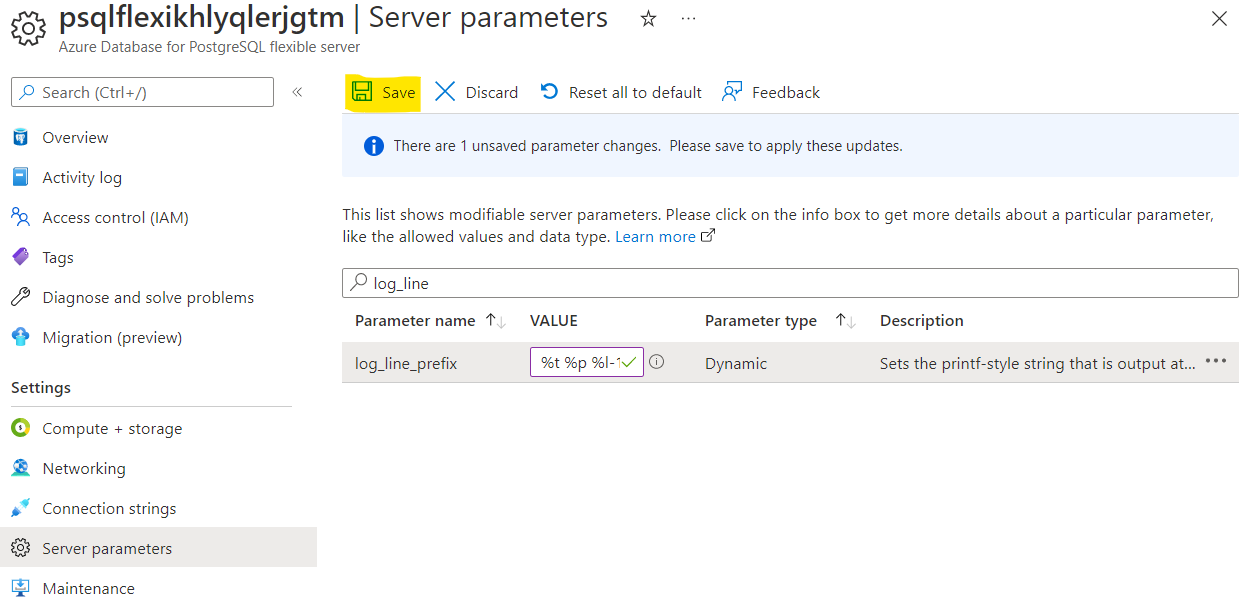
After the change hit the “Save”:
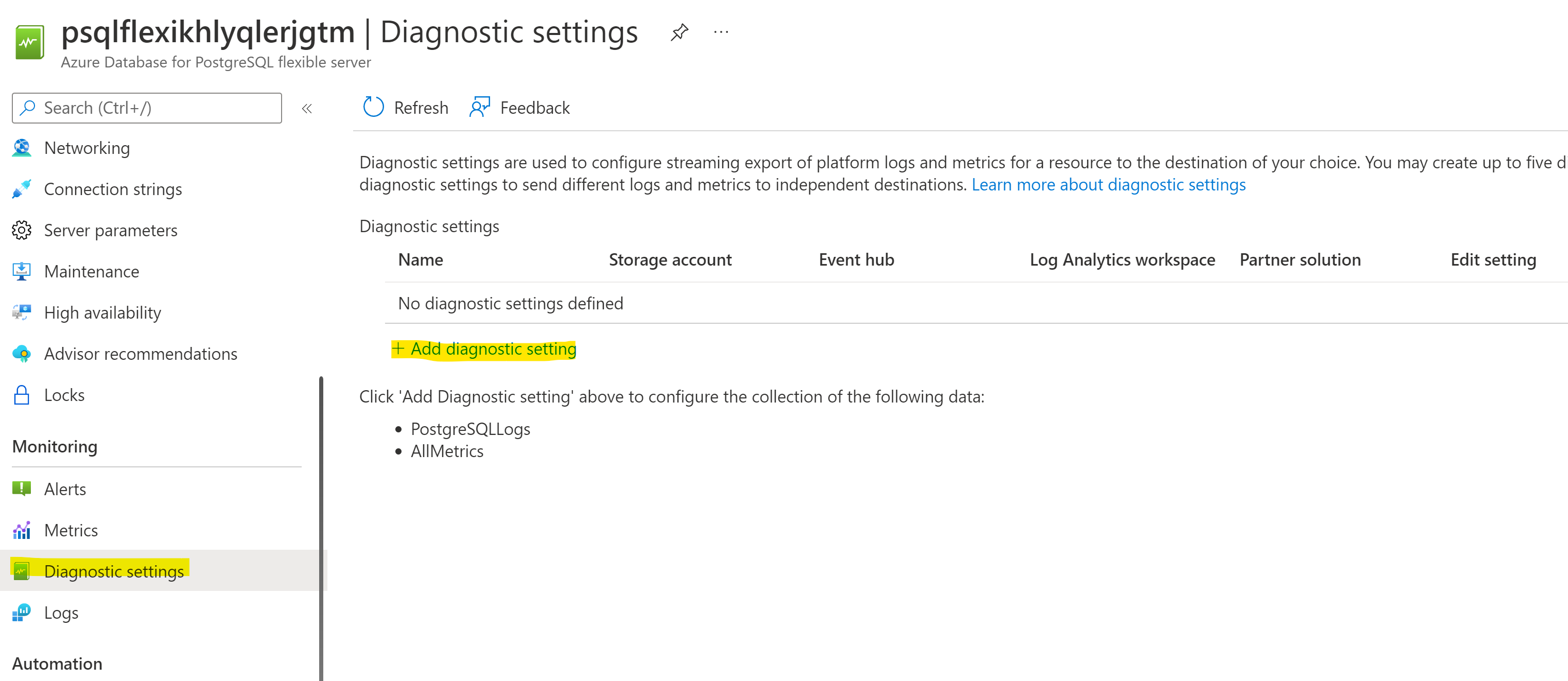
Configuring Diagnostic Settings
Navigate to Diagnostic settings page in the Azure Portal and add a new one with Storage Account destination:
Choose a name of your choice for your setting, redirect the logs to the storage account (“Archive to a storage account” checkbox) and choose “PostgreSQLLogs” as a category:
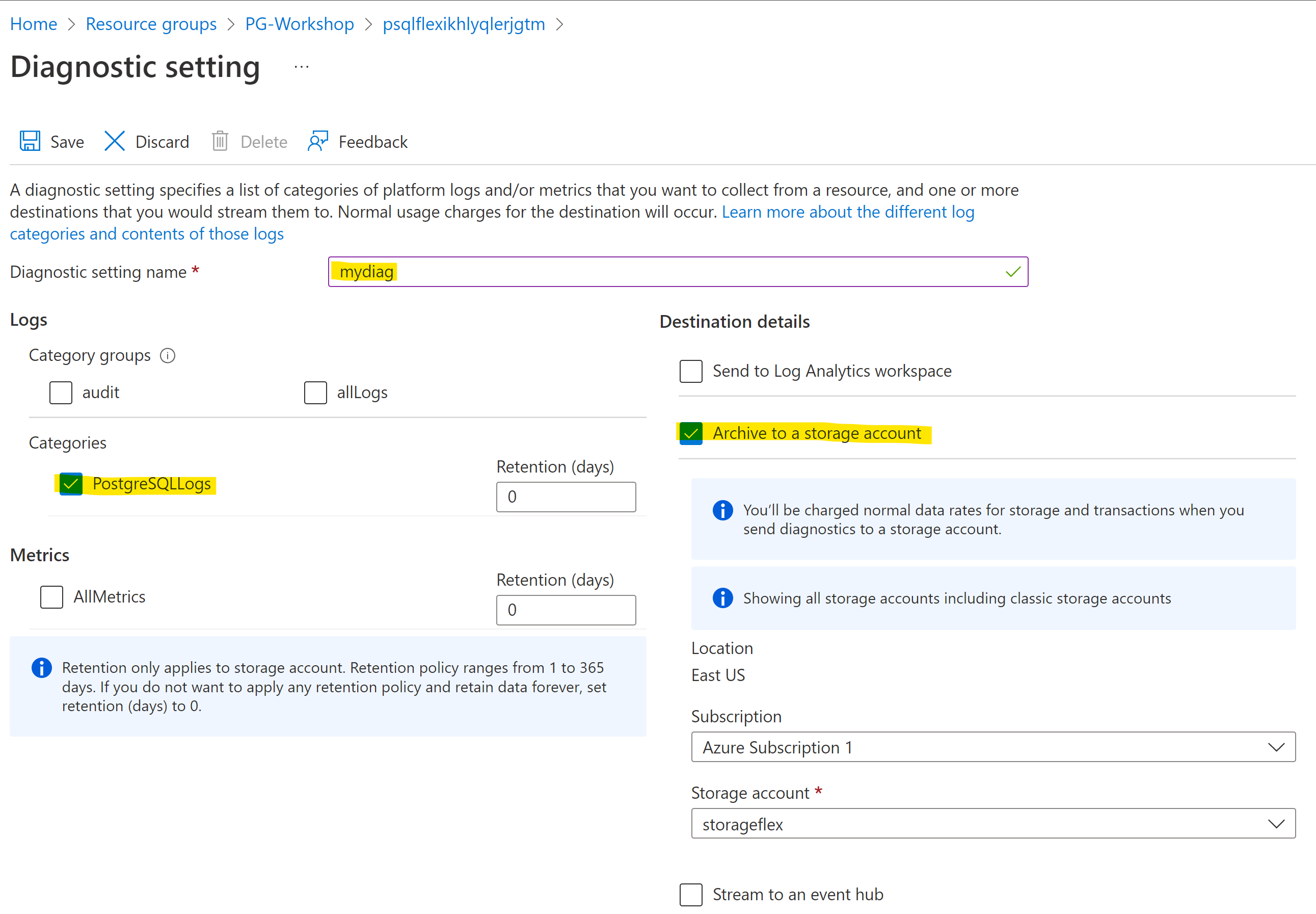
Hit save button.
Mounting Storage Account to VM
If you finished the pgaudit secion in the previous section you can skip to Install PgBadger
In this section you will mount Storage Account to your dns VM to be able to easier manipulate on log files.
First let’s download and install necessary packages. Feel free to simply copy and paste the following commands:
sudo rpm -Uvh https://packages.microsoft.com/config/rhel/8/packages-microsoft-prod.rpm
sudo dnf -y install blobfuse
sudo mkdir /mnt/ramdisk
sudo mount -t tmpfs -o size=16g tmpfs /mnt/ramdisk
sudo mkdir /mnt/ramdisk/blobfusetmp
sudo chown <your VM admin> /mnt/ramdisk/blobfusetmp
Authorize access to your storage account
You can authorize access to your storage account by using the account access key, a shared access signature, a managed identity, or a service principal. Authorization information can be provided on the command line, in a config file, or in environment variables.
For this exercise we will authorize with the account access keys and storing them in a config file. The config file should have the following format:
accountName myaccount
accountKey storageaccesskey
containerName insights-logs-postgresqllogs
Please prepare the following file in editor of your choice. Values for the accountName and accountKey you will find in the Azure Portal. Please navigate to your storage account in the portal and then choose Access keys page:
Copy accountName and accountKey and paste it to the file. Copy the content of your file and paste it to the fuse_connection.cfg file in your home directory, then mount your storage account container onto the directory in your VM:
vi fuse_connection.cfg
chmod 600 fuse_connection.cfg
mkdir ~/mycontainer
sudo blobfuse ~/mycontainer --tmp-path=/mnt/resource/blobfusetmp --config-file=/home/<your VM admin>/fuse_connection.cfg -o attr_timeout=240 -o entry_timeout=240 -o negative_timeout=120
sudo -i
cd /home/<your VM admin>/mycontainer/
ls # check if you see mounted container
# Please use tab key for directory autocompletion; do not copy and paste!
cd resourceId\=/SUBSCRIPTIONS/<your subscription id>/RESOURCEGROUPS/PG-WORKSHOP/PROVIDERS/MICROSOFT.DBFORPOSTGRESQL/FLEXIBLESERVERS/PSQLFLEXIKHLYQLERJGTM/y\=2022/m\=06/d\=16/h\=09/m\=00/
ls
less PT1H.json
You should see some logs being generated.
Install PgBadger
As the last step we need to install PgBadger. Feel free to copy and paste the following commands:
sudo -i
dnf install -y perl perl-devel
wget https://github.com/darold/pgbadger/archive/v11.8.tar.gz
tar xzf v11.8.tar.gz
cd pgbadger-11.8/
perl Makefile.PL
make && make install
Generate pgbadger report
Choose the file you want to generate pgBadger from and go to the directory where the chosen PT1H.json file is stored, for instance:
cd /home/pgadmin/mycontainer/resourceId=/SUBSCRIPTIONS/***/RESOURCEGROUPS/PG-WORKSHOP/PROVIDERS/MICROSOFT.DBFORPOSTGRESQL/FLEXIBLESERVERS/PSQLFLEXIKHLYQLERJGTM/y=2022/m=05/d=23/h=09/m=00
and run the following commands to extract the message value from json:
cut -f9- -d\: PT1H.json | cut -f1 -d\} | sed -e 's/^."//' -e 's/"$//' > 01
cat 01| sed 's/\\n/\n/g'>02
cat 02| sed 's/\\"/"/g'>03
You are ready to generate your first pgBadger report:
/usr/local/bin/pgbadger --prefix='%t %p %l-1 db-%d,user-%u,app-%a,client-%h ' 03 -o pgbadgerReport.html
Now you can download your report either from Azure Portal or by using scp command:
Multiversion Concurrency Control, MVCC
This section describes the behavior of the PostgreSQL database system when two or more sessions try to access the same data at the same time. The goals in that situation are to allow efficient access for all sessions while maintaining strict data integrity. Every developer of database applications and DBA should be familiar with the topics covered in this chapter.
Task Hints
- We will use the portal to change the PostgreSQL parameters.
- Inspect the table size and see the impact of autovacuum.
Tasks
Inspect and change server paramerters
You can list, show, and update configuration parameters for an Azure Database for PostgreSQL server through the Azure portal.
- Go to the Azure PostgreSQL resource
- Change Autovacuum server parameter to off and Save

On psql or your favorite IDE/GUI
Check Autovacuum setting:
SHOW AUTOVACUUM ;
It should return this:
postgres=> SHOW AUTOVACUUM ;
autovacuum
------------
off
(1 row)
postgres=>
Make sure that you have the random_data table
drop TABLE IF EXISTS random_data;
CREATE TABLE random_data AS
SELECT s AS first_column,
md5(random()::TEXT) AS second_column,
md5((random()/2)::TEXT) AS third_column
FROM generate_series(1,500000) s;
In case you wanted to see the path of the table:
SELECT pg_relation_filepath('random_data');
Output
pg_relation_filepath
----------------------
base/14417/16507
(1 row)
Display the table size:
SELECT pg_relation_size('random_data');
Output
postgres=> SELECT pg_relation_size('random_data');
pg_relation_size
------------------
50569216
(1 row)
Display the table size in MB:
SELECT pg_size_pretty(pg_relation_size('random_data'));
Output
postgres=> SELECT pg_size_pretty(pg_relation_size('random_data'));
pg_size_pretty
----------------
48 MB
(1 row)
Inserting more records in the random_data
INSERT INTO random_data
SELECT s,
md5(random() :: TEXT),
md5((random() / 2) :: TEXT)
FROM generate_series(1, 1000000) s;
SELECT count(*) FROM random_data;
Output
postgres=> INSERT INTO random_data
postgres-> SELECT s,
postgres-> md5(random() :: TEXT),
postgres-> md5((random() / 2) :: TEXT)
postgres-> FROM generate_series(1, 1000000) s;
INSERT 0 1000000
postgres=>
postgres=> SELECT count(*) FROM random_data;
count
---------
1500000
(1 row)
Check the table size after the insersion
SELECT pg_size_pretty(pg_relation_size('random_data'));
Output
postgres=> SELECT pg_size_pretty(pg_relation_size('random_data'));
pg_size_pretty
----------------
145 MB
(1 row)
postgres=>
Notice, that there is a signigcant increase in the table size. Now, delete all the recrods:
DELETE from random_data;
Output
postgres=> DELETE from random_data;
DELETE 1500000
Checking the table size after deletion of the records:
SELECT pg_size_pretty(pg_relation_size('random_data'));
Output
postgres=> SELECT pg_size_pretty(pg_relation_size('random_data'));
pg_size_pretty
----------------
145 MB
(1 row)
You can see that the table size is still 145 MB, if we started the VACUUM process things would change:
VACUUM VERBOSE random_data;
Output
postgres=> VACUUM VERBOSE random_data;
INFO: vacuuming "public.random_data"
INFO: "random_data": removed 1500000 row versions in 18519 pages
INFO: "random_data": found 1500000 removable, 0 nonremovable row versions in 18519 out of 18519 pages
DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 595
There were 0 unused item pointers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 0.25 s, system: 0.00 s, elapsed: 0.23 s.
INFO: "random_data": truncated 18519 to 0 pages
DETAIL: CPU: user: 0.06 s, system: 0.01 s, elapsed: 0.04 s
INFO: vacuuming "pg_toast.pg_toast_16507"
INFO: index "pg_toast_16507_index" now contains 0 row versions in 1 pages
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
INFO: "pg_toast_16507": found 0 removable, 0 nonremovable row versions in 0 out of 0 pages
DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 596
There were 0 unused item pointers.
Skipped 0 pages due to buffer pins, 0 frozen pages.
0 pages are entirely empty.
CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
VACUUM
postgres=> SELECT pg_size_pretty(pg_relation_size('random_data'));
pg_size_pretty
----------------
0 bytes
(1 row)
- Check the table size after applying the Vacuum process:
SELECT pg_size_pretty(pg_relation_size('random_data'));
Output
postgres=> SELECT pg_size_pretty(pg_relation_size('random_data'));
pg_size_pretty
----------------
0 bytes
(1 row)
SQL Characteristic
Partial Index
Let’s create a new table in quiz database and load it with some data:
CREATE SCHEMA IF NOT EXISTS games;
SET SEARCH_PATH TO games;
DROP TABLE IF EXISTS games;
CREATE TABLE games
(
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
start_time TIMESTAMP NOT NULL DEFAULT now(),
end_time TIMESTAMP NOT NULL,
players INTEGER[] NOT NULL,
winner INTEGER,
is_activ BOOLEAN DEFAULT TRUE
);
INSERT INTO games (start_time, end_time, players, winner, is_activ)
SELECT d, d + '1 hour', ('{' || n || ',' || n + 4 || '}')::INT[], n, TRUE
FROM generate_series(1, 10000) n,
generate_series('2021-01-01'::TIMESTAMP, now()::TIMESTAMP, '1 day'::INTERVAL) d
;
Check how many rows were added:
SELECT count(*) FROM games;
Update some of the rows so is_activ field will have value FALSE for all the rows where start_time is different than today:
UPDATE games SET is_activ = FALSE WHERE start_time::date <> CURRENT_DATE;
Check how many of the rows have flag is_activ set to TRUE:
SELECT count(*) FROM games WHERE is_activ;
Run the same query 4-5 times again and check it’s execution time:
SELECT count(*) FROM games WHERE is_activ;
Were subsequent executions faster than the first and could you explain why?
Let’s create a partial index using is_activ column:
CREATE INDEX ON games(id) WHERE is_activ;
Check again how much time this query needs to be executed:
SELECT count(*) FROM games WHERE is_activ;
JSONB
Create a table containing JSONB column and populate it with some data:
CREATE TABLE products
(
name TEXT,
attributes JSONB
);
INSERT INTO products (name, attributes)
VALUES ('Leffe Blonde Ale',
'{
"category": "Golden / Blonde Ale",
"region": "Belgium",
"ABV": 6.6
}');
Query the table using JSON operators:
SELECT name, attributes -> 'ABV'
FROM products;
SELECT name, attributes ->> 'ABV'
FROM products
WHERE attributes ->> 'region' = 'Belgium';
Create the GIN index on the table:
CREATE INDEX ON products USING gin(attributes);
Statistics and Query Planning
EXPLAIN
Recreate the random_data table:
DROP TABLE IF EXISTS random_data;
CREATE TABLE random_data
AS
SELECT s AS first_column,
md5(random() :: TEXT) AS second_column,
md5((random() / 2) :: TEXT) AS third_column
FROM generate_series(1, 500000) s;
Run EXPLAIN command to see what’s the execution plan of ‘SELECT *’ query:
EXPLAIN TABLE random_data;
Output:
Seq Scan on random_data (cost=0.00..11420.05 rows=524705 width=68)
Check the statistics that Postgres currently has for random_data table:
SELECT relpages, reltuples FROM pg_class WHERE relname = 'random_data';
Output:
relpages | reltuples
----------+-----------
0 | 0
(1 row)
Run the VACUUM ANALYZE command against random_data and check the statisctics again:
VACUUM ANALYSE random_data;
SELECT relpages, reltuples FROM pg_class WHERE relname = 'random_data';
Output:
relpages | reltuples
----------+-----------
6173 | 500000
(1 row)
Check the EXPLAIN output again:
EXPLAIN TABLE random_data;
Are the numbers more accurate?
Output:
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on random_data (cost=0.00..11173.00 rows=500000 width=70)
(1 row)
Let’s calculate the cost as Postgres query planner does:
SELECT relpages * current_setting('seq_page_cost')::numeric
+ reltuples * current_setting('cpu_tuple_cost')::numeric
FROM pg_class
WHERE relname = 'random_data';
Output:
?column?
----------
11173
(1 row)
As you can see that’s the same cost as shown in the EXPLAIN output;
Let’s add a WHERE condition to the query:
EXPLAIN SELECT * FROM random_data WHERE first_column < 2000;
Output:
Gather (cost=1000.00..9971.17 rows=1940 width=70)
Workers Planned: 2
-> Parallel Seq Scan on random_data (cost=0.00..8777.17 rows=808 width=70)
Filter: (first_column < 2000)
Let’s add ANALYZE to EXPLAIN clause:
EXPLAIN ANALYSE SELECT * FROM random_data WHERE first_column < 2000;
Output:
Gather (cost=1000.00..9971.17 rows=1940 width=70) (actual time=0.498..727.918 rows=1999 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on random_data (cost=0.00..8777.17 rows=808 width=70) (actual time=0.004..83.350 rows=666 loops=3)
Filter: (first_column < 2000)
Rows Removed by Filter: 166000
Planning Time: 0.098 ms
Execution Time: 728.032 ms
Now not only the plan was shown but also the query was executed.
Create an index and see how the execution plan has changed:
CREATE INDEX ON random_data(first_column);
EXPLAIN ANALYZE SELECT * FROM random_data WHERE first_column < 2000;
Output:
Index Scan using random_data_first_column_idx on random_data (cost=0.42..86.67 rows=1957 width=70) (actual time=0.012..0.330 rows=1999 loops=1)
Index Cond: (first_column < 2000)
Planning Time: 0.107 ms
Execution Time: 0.421 ms
Why Index Scan not Index Only Scan was used?
See the execution plan for a selfjoin:
EXPLAIN ANALYZE
SELECT t5.*
FROM random_data
JOIN random_data t5 USING (first_column)
WHERE t5.first_column < 2000;
Output:
Nested Loop (cost=0.84..5543.32 rows=1957 width=70) (actual time=0.025..3.809 rows=1999 loops=1)
-> Index Scan using random_data_first_column_idx on random_data t5 (cost=0.42..86.67 rows=1957 width=70) (actual time=0.016..0.422 rows=1999 loops=1)
Index Cond: (first_column < 2000)
-> Index Only Scan using random_data_first_column_idx on random_data (cost=0.42..2.78 rows=1 width=4) (actual time=0.001..0.001 rows=1 loops=1999)
Index Cond: (first_column = t5.first_column)
Heap Fetches: 0
Planning Time: 0.331 ms
Execution Time: 3.928 ms
Why Nested Loop was used?
Check if planner has chosen the right plan by disabling the nested loop:
SET ENABLE_NESTLOOP TO OFF;
EXPLAIN ANALYZE
SELECT t5.*
FROM random_data
JOIN random_data t5 USING (first_column)
WHERE t5.first_column < 2000;
Output:
Gather (cost=1111.13..10352.56 rows=1957 width=70) (actual time=0.965..114.698 rows=1999 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Hash Join (cost=111.13..9156.86 rows=815 width=70) (actual time=35.316..67.464 rows=666 loops=3)
Hash Cond: (random_data.first_column = t5.first_column)
-> Parallel Seq Scan on random_data (cost=0.00..8256.33 rows=208333 width=4) (actual time=0.011..38.918 rows=166667 loops=3)
-> Hash (cost=86.67..86.67 rows=1957 width=70) (actual time=0.786..0.787 rows=1999 loops=3)
Buckets: 2048 Batches: 1 Memory Usage: 216kB
-> Index Scan using random_data_first_column_idx on random_data t5 (cost=0.42..86.67 rows=1957 width=70) (actual time=0.038..0.442 rows=1999 loops=3)
Index Cond: (first_column < 2000)
Planning Time: 0.219 ms
Execution Time: 114.823 ms
Disable also Hash Joins:
SET ENABLE_HASHJOIN TO OFF;
EXPLAIN ANALYZE
SELECT t5.*
FROM random_data
JOIN random_data t5 USING (first_column)
WHERE t5.first_column < 2000;
Output:
Gather (cost=1000.85..11896.00 rows=1957 width=70) (actual time=0.446..287.762 rows=1999 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Merge Join (cost=0.84..10700.30 rows=815 width=70) (actual time=13.313..16.500 rows=666 loops=3)
Merge Cond: (random_data.first_column = t5.first_column)
-> Parallel Index Only Scan using random_data_first_column_idx on random_data (cost=0.42..10079.76 rows=208333 width=4) (actual time=12.803..12.873 rows=667 loops=3)
Heap Fetches: 0
-> Index Scan using random_data_first_column_idx on random_data t5 (cost=0.42..86.67 rows=1957 width=70) (actual time=0.085..0.552 rows=1999 loops=3)
Index Cond: (first_column < 2000)
Planning Time: 0.255 ms
Execution Time: 287.901 ms
Which algorithm was the fastest for this query and why?
work_mem Setting
Run EXPLAIN command to see what’s the execution plan of the SELECT query that requires sorting:
EXPLAIN ANALYSE SELECT second_column FROM random_data ORDER BY 1 DESC;
Output:
Sort (cost=73824.53..75136.30 rows=524705 width=32) (actual time=10705.361..14201.555 rows=500000 loops=1)
Sort Key: second_column DESC
Sort Method: external merge Disk: 21096kB
-> Seq Scan on random_data (cost=0.00..11420.05 rows=524705 width=32) (actual time=0.018..808.240 rows=500000 loops=1)
Planning Time: 0.087 ms
Execution Time: 14378.488 ms
As you see external merge was used as a sort method. It means that your data were sorted on the disk. This is because work_mem value was to small to sort the data in memory.
Check the current value of work_mem:
SHOW work_mem;
How much memory do you need to sort the data in RAM?
You can change the work_mem value just for the session to try it out. Set the proper value and try to rerun the query.
SET work_mem = '10MB';
After chosing the right work_mem value you will see that execution plan has changed:
Sort (cost=61270.03..62581.80 rows=524705 width=32) (actual time=11884.004..12146.057 rows=500000 loops=1)
Sort Key: second_column DESC
Sort Method: quicksort Memory: 51351kB
-> Seq Scan on random_data (cost=0.00..11420.05 rows=524705 width=32) (actual time=0.013..579.455 rows=500000 loops=1)
Planning Time: 0.051 ms
Execution Time: 12206.274 ms
Now quicksort Memory was used instead of external merge. Why more memory is needed for the same sort operation in memory than on the disk?
Clean up
Once you’re done with the workshop, make sure to delete the resources you created. You can read through manage Azure resources by using the Azure portal or manage Azure resources by using Azure CLI for more details.
Contributors
The following people have contributed to this workshop, thanks!





